Geçen hafta zaman çizelgemde bir cümle gördüm: "Yeni model X, GPT-5.5'i geçti." Altında bir tablo, yeşil bir hücre, iki puanlık bir fark. Bir an heyecanlandım — sonra durdum. Neyi geçti? Hangi testte, kaç örnekle, kim ölçtü, model o testi daha önce gördü mü? Belli değildi. O yeşil hücre bir mühendislik zaferi de olabilirdi, bir pazarlama cümlesi de, ölçüm gürültüsü de. Cümleyi okumak için elimde bir gramer yoktu.
Bu yazı o grameri kurmakla ilgili. Önceki dört yazıda modelin içine baktık — kavramlar, mimari (attention, RoPE), eğitim (pretraining → SFT → DPO → GRPO), çalıştırma (KV cache, speculative decoding). Bu yazı yeni bir soru soruyor: modeli nasıl ölçüyoruz? Ve neden bu ölçüm, göründüğünden çok daha zor okunuyor?
İddia şu: 2026'da "şu model şunu geçti" cümlelerinin çoğu, dikkatli okununca söylediği şeyi söylemiyor. Benchmark'lar doyuyor, contamination skoru şişiriyor, Arena stili ödüllendiriyor, reasoning modelleri aynı modelden bambaşka sayılar üretiyor, üç tablo aynı hafta üç farklı "en iyi" ilan ediyor. Hiçbiri sektörün çöktüğü anlamına gelmiyor — sadece bir skorun, yanında üç beş soru sorulmadan okunamayacağını gösteriyor. (Kapsam: bu yazı metin-tabanlı LLM benchmark'larıyla sınırlı — multimodal değerlendirme, örneğin MMMU, ayrı bir konudur.) On iki katman var; sırayla.
1. Benchmark Hayvanat Bahçesi — Neyi Ölçüyoruz?
Bir LLM'i değerlendiren test listesi uzun ve her biri farklı şey ölçüyor. Hızlı bir tur:
- MMLU (Hendrycks 2020) — 57 konuda çoktan seçmeli bilgi; yıllarca "genel yetenek" göstergesi sayıldı.
- GSM8K (Cobbe 2021) — ilkokul matematiği, çok adımlı aritmetik. MATH (2021) — yarışma matematiği.
- HumanEval / MBPP (2021) — docstring'den Python fonksiyonu üret, birim testlerle kontrol et.
- HellaSwag / ARC / WinoGrande (2018-19) — sağduyu, fen, zamir çözümleme.
- GPQA Diamond (Rein 2023) — PhD uzmanların yazdığı, kasıtlı "Google-proof" fen soruları.
- IFEval (2023) — kodla doğrulanabilir talimat takibi. MT-Bench / AlpacaEval 2 — LLM'i hakem yapıp sohbet puanlama.
Bu listenin atası, tek bir skora karşı yazılmış bir manifesto: Liang ve ekibinin HELM'i (2022). Derdi, herkesin karşılaştırılamaz sayılar yayınlamasıydı:
"Prior to HELM, models on average were evaluated on just 17.9% of the core HELM scenarios ... We improve this to 96.0%."
HELM tek bir doğruluk yerine yedi metrik (accuracy, calibration, robustness, fairness, bias, toxicity, efficiency) önerdi — çünkü "en doğru model" aynı zamanda en az kalibre, en toksik model olabilir. Yazının ilk dersi: tek eksen yanıltır. Bir incelik daha: aynı testin skoru, onu koşturan değerlendirme harness'ına göre bile oynar — lm-eval-harness, HELM ve üreticinin kendi prompt'u aynı MMLU'da farklı sayı üretebilir (few-shot sayısı, hatta cevabı metinden ayıklama yöntemi puanı kaydırır). "Aynı benchmark" her zaman aynı ölçüm değildir. Ama testlerin asıl sorunu başka: hepsi yaşlanıyor.
2. Satürasyon — Benchmark'ların Ömrü Vardır
HellaSwag 2019'da çıktığında makalesi "insanlar için aşikâr (>%95), en iyi modeller zorlanıyor (<%48)" diyordu. Bugün frontier modeller HellaSwag'da ~%95+. Aynı hikâye MMLU'da: 2020'de GPT-3 %43.9'du (tahmini insan tavanı %89.8), 2023'te GPT-4 %86.4, 2024'te modeller %90'ı geçti, 2025'te MMLU "daha zor alternatifler lehine kısmen emekliye ayrıldı." Bir test frontier modelleri ayırt edemez hale geldiğinde ölür; buna satürasyon denir.
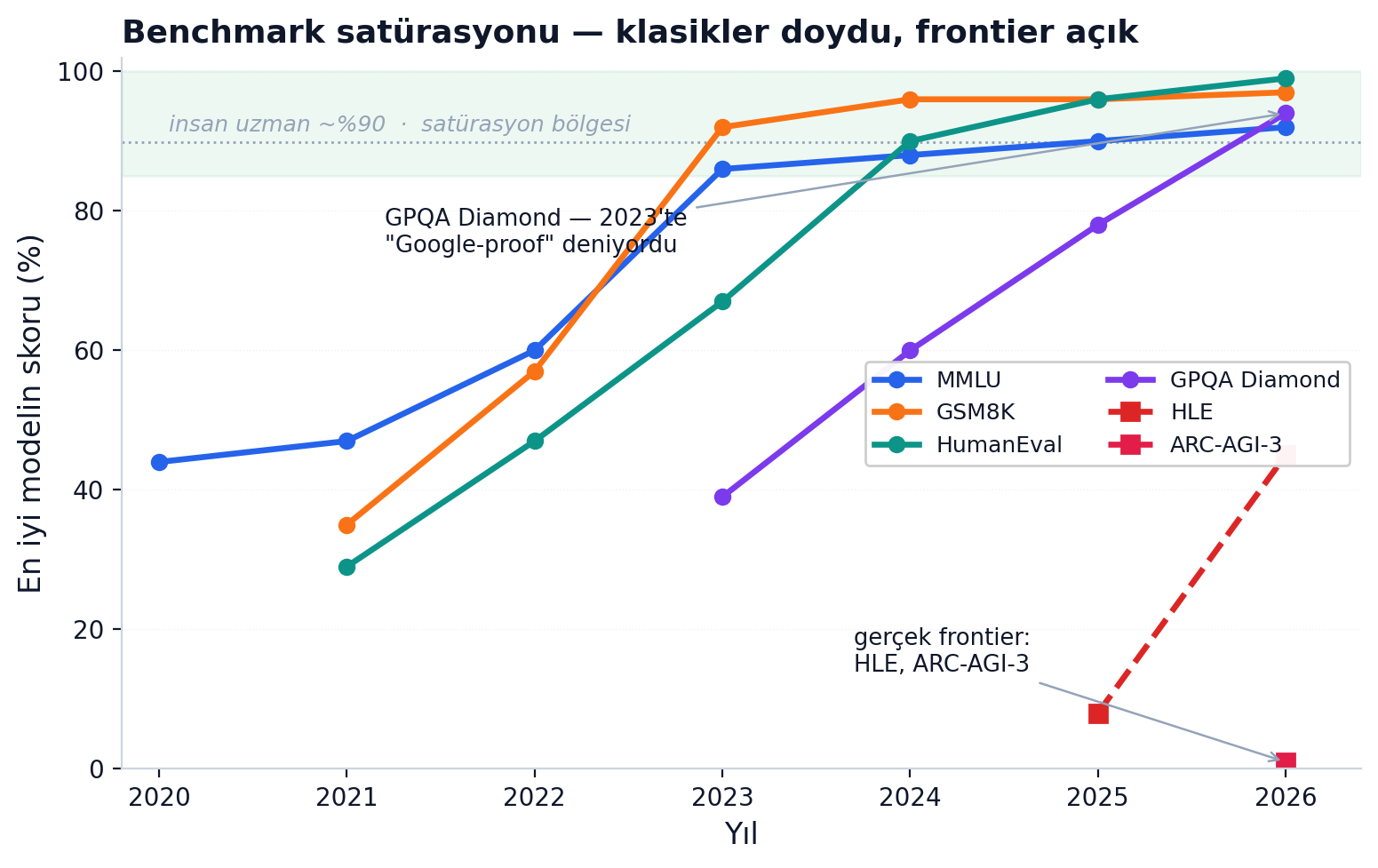
Üst şeritte (≥%85) sıkışan eğriler doymuş benchmark'lar. Asıl sürpriz mor çizgide: GPQA Diamond. 2023'te "PhD-seviyesi, Google-proof, doymaz" diye lanse edilmişti — uzmanlar %65, GPT-4 %39:
"experts who ... reach 65% accuracy ... while highly skilled non-expert validators only reach 34% ... despite ... unrestricted access to the web (i.e., the questions are 'Google-proof'). ... our strongest GPT-4 based baseline achieving 39% accuracy."
Mayıs 2026'da GPQA Diamond'da tepe %94.1 (Gemini 3.1 Pro, Artificial Analysis ölçümü; llm-stats aynı hafta daha yükseğini — Claude Mythos Preview ile %94.6'yı — gösteriyor, yani "tepe" bile tabloya göre değişiyor). "Çözülemez" test ~2.5 yılda insan-uzman tavanının çok üstüne çıktı. MATH de aynı kaderi yaşadı: 2021 makalesi açıkça "scaling is not currently solving MATH" demişti — ~3 yıl sonra reasoning modelleri MATH'i pratikte çözdü.
İki ince nokta. Birincisi, doygunluğa yakın bir testte kalan 1-2 puan gürültü olabilir: MadryLab'in GSM8K-Platinum'u, ~%95 platosunun çoğunun etiket gürültüsü olduğunu gösterdi — set temizlenince Claude 3.7 (2 hata) ile Llama 405B (17 hata) arasında 8 kat fark açıldı; gürültülü orijinal bunu gizliyordu. İkincisi, testin kendisi hatalı olabilir: MMLU'nun elle incelenen analizinde sorular ~%6.5 hatalı çıktı (Virology'de %57). Yani MMLU'da %100 zaten imkânsız — yüksek skoru mutlak okumak, testi kusursuz saymaktır.
3. Yeni Nesil — Doymasın Diye Tasarlananlar
Klasikler doyunca yarış daha zor testlere kaydı. Üçü öne çıkıyor.
Humanity's Last Exam (HLE) — Center for AI Safety + Scale AI, 2025. 1.000+ uzmanın yazdığı 2.500 soru, "kapalı-uçlu akademik sınavların sonuncusu" olarak tasarlandı; gerekçe açık: "LLMs now achieve over 90% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities." HLE'de tepe hâlâ düşük: Gemini 3.1 Pro %44.7, arkasında GPT-5.5 (~%44) (Artificial Analysis); GPT-4o ise 2025 lansmanında yalnızca %2.7 almıştı. (Kaynağa göre tepe oynuyor: Scale aynı Gemini'yi farklı ayarla %46.4 raporluyor.) Asıl çarpıcı veri ikinci sütunda: kalibrasyon hatası lansmanda %80'in üzerindeydi, bugünün frontier modellerinde hâlâ ~%40-55. Yani model yanlışken bile aşırı kendinden emin — "bilmediğini biliyor mu?" sorusunun yanıtı çoğu zaman "hayır."
ARC-AGI — Chollet'in 2019'daki "On the Measure of Intelligence"ından doğdu; tezi skill ≠ zekâ:
"skill is heavily modulated by prior knowledge and experience: unlimited priors or unlimited training data allow experimenters to 'buy' arbitrary levels of skills ... in a way that masks the system's own generalization power."
Prensip "insan için kolay, AI için zor." ARC-AGI-1, 2020'de GPT-3 ile %0, 2024'te GPT-4o ile ancak %5'ti — sonra o3 geldi (9. bölüm). Chollet'in uyarısı önemli: "Passing ARC-AGI does not equate to achieving AGI ... o3 still fails on some very easy tasks."
SWE-bench Verified — gerçek GitHub issue'larını çözme testi. Orijinal SWE-bench (2023) o kadar zordu ki Claude 2 issue'ların yalnızca %1.96'sını çözüyordu. Ama asıl ders "Verified"da: OpenAI orijinal seti insan denetçilerden geçirince örneklerin %68.3'ünü attı — soru yetersiz tanımlı ya da birim testleri doğru çözümü haksızca yanlış sayıyordu. Üçte ikisi bozuktu; bir benchmark kaynağında kırık olabilir.
Ama hikâyenin asıl kıvrımı 2026'da geldi: temizlenmiş "Verified" bile dayanamadı. 23 Şubat 2026'da OpenAI, SWE-bench Verified skorlarını raporlamayı bıraktığını açıkladı — gerekçe tam da bu yazının tezi. Birincisi contamination: GPT-5.2, Claude Opus 4.5 ve Gemini 3 Flash Preview'in üçü de, yalnızca problemin ID'sini prompt olarak verince orijinal "altın-yama" çözümünü ezberden kelimesi kelimesine üretebiliyordu. İkincisi testlerin kendisi: OpenAI'nin değerlendirme ekibi, modellerin ısrarla çözemediği 138 problemi yeniden incelettiğinde %60'tan fazlasının "olduğu gibi çözülemez" olduğunu buldu (49 test fazla dar tanımlıydı — sözde belirtilmemiş implementasyon detaylarını dayatıp doğru çözümleri reddediyordu; 26'sı hiç sözü edilmeyen ekstra özellikler istiyordu). OpenAI'nin kendi sonucu: benchmark "doymuş ve ağır biçimde kontamine," artık kodlama yeteneğindeki ilerlemeyi düzgün ölçmüyor — iyileşmeler giderek gerçek beceriyi değil, modelin eğitimde benchmark'a ne kadar maruz kaldığını yansıtıyor. Önerilen halefi SWE-bench Pro'da fark çıplak: Verified'da %70+ alan modeller Pro'da ~%23'e iniyor. Kapanıştaki koşu bandı metaforu burada birebir gerçek oldu — kaynağı bir kez temizlenmiş bir benchmark bile contamination'a yeniliyor.
4. Long-Context Yanılsaması — "1 Milyon Token" Ne Demek?
Modeller "1M token bağlam" diye reklam yapıyor; bu sayı neredeyse her zaman yanıltıcı. En yaygın test NIAH (Needle in a Haystack): uzun metne bir cümle saklayıp modelden bulmasını istemek. Sorun, NIAH'ın gerekli ama yetersiz olması — tek bir gerçeği kelimesi kelimesine getirmeyi ölçüyor, bağlam üzerinde akıl yürütmeyi değil. NVIDIA'nın RULER makalesi açık:
"While these models all claim context sizes of 32K tokens or greater, only half of them can maintain satisfactory performance at the length of 32K."
RULER'ın "etkin bağlam" tablosu yıkıcı: Yi-34B 200K reklam ediyor ama etkin bağlamı 32K; DBRX 32K diyor, 8K'da çöküyor.
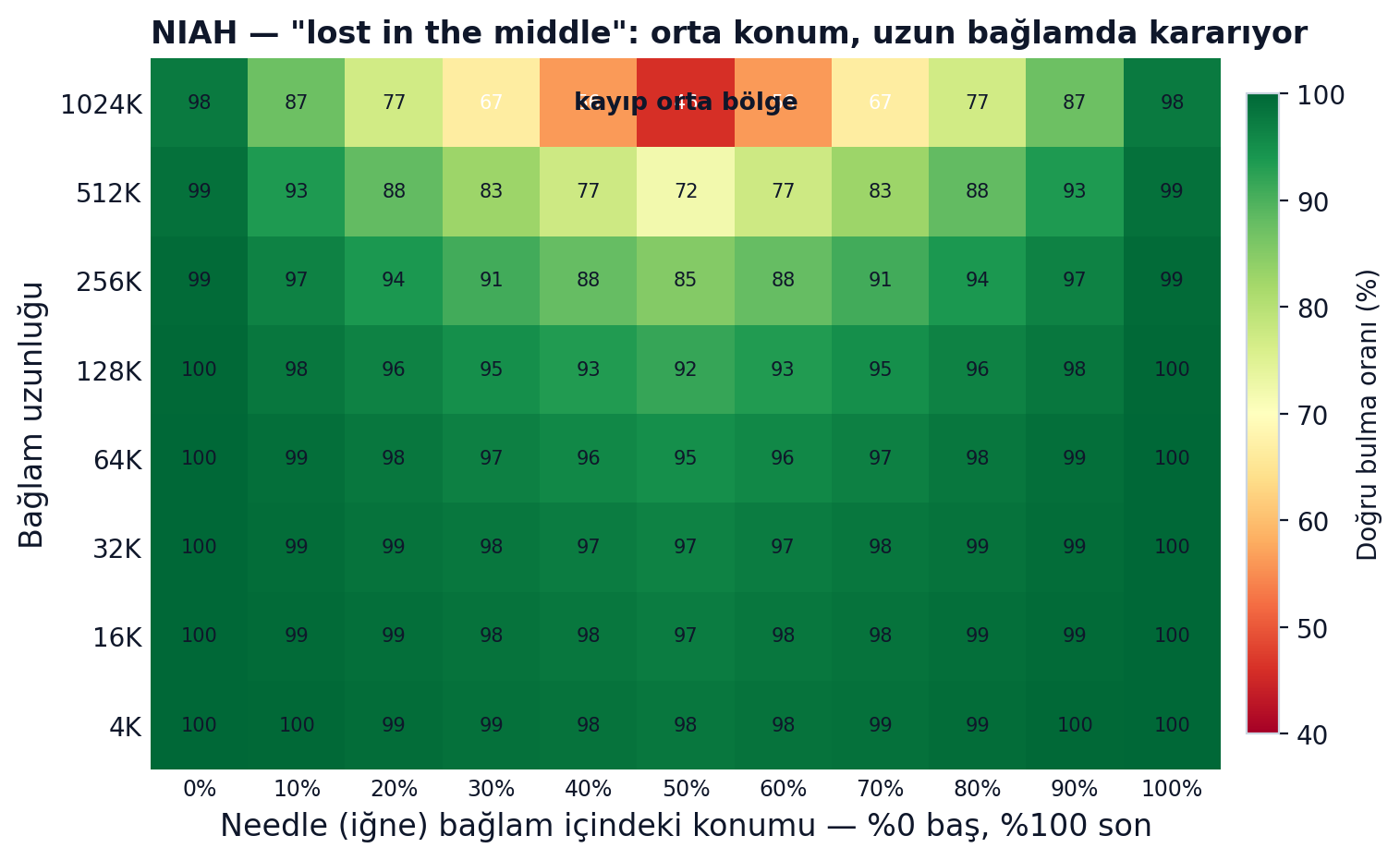
Üstüne bir de "lost in the middle" var (Liu ve ekibi, 2023):
"performance is often highest when relevant information occurs at the beginning or end of the input context, and significantly degrades when models must access relevant information in the middle of long contexts."
En kötü senaryoda GPT-3.5'in çok-belgeli QA performansı, ilgili bilgi ortaya konunca hiç belge verilmemiş halinden daha düşük çıkabiliyor. "1M token" diye satın aldığın şey ortada bir kör nokta ile geliyor.
5. Contamination — Test Sızıntısı
En sinsi soruna geldik: bir model test sorusunu eğitim verisinde gördüyse, yüksek skoru "anlama" değil "hatırlama" olabilir.
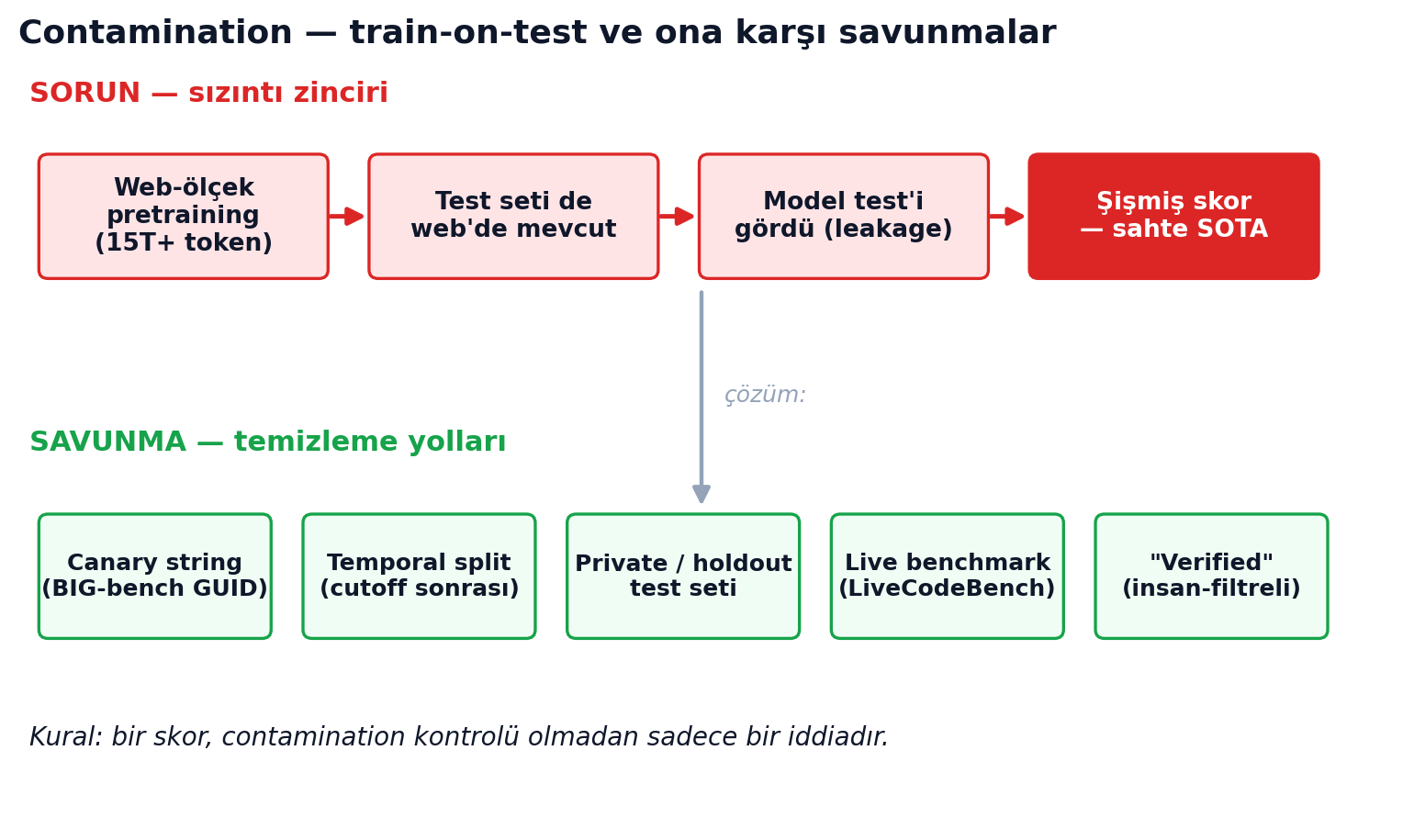
Sainz ve ekibinin 2023'teki manifestosu tanımı veriyor: "The worst kind of data contamination happens when a [LLM] is trained on the test split of a benchmark, and then evaluated in the same benchmark. ... Contamination causes an overestimation of the performance of a contaminated model." Teorik değil: Scale AI'ın GSM1k çalışması GSM8K'yı aynalayan 1.000 yeni soru yazdı ve bazı model ailelerinde %8'e varan düşüş ölçtü — şişen skorla "test setini hatırlama" eğilimi doğrudan korele (Spearman r²=0.36).
Daha rahatsız edici olanı: yaygın savunma olan n-gram filtreleme yetersiz. Yang ve ekibinin "Rephrased Samples" çalışması (2023; LMSYS'in llm-decontaminator aracı buradan doğdu), test sorularını parafraz ederek veya çevirerek filtreyi atlattı:
"simple variations of test data (e.g., paraphrasing, translation) can easily bypass these decontamination measures ... a 13B model can easily overfit a test benchmark and achieve drastically high performance, on par with GPT-4."
13B'lik bir model, test setini parafrazla ezberleyip GPT-4'e yetişiyor; aynı çalışma RedPajama ve StarCoder'da HumanEval'in %8-18'inin zaten mevcut olduğunu buldu. İcat edilen canary string (BIG-bench GUID'i) bile sızıyor — GPT-4-base ve Claude 3.5 Sonnet'in onu üretebildiği görüldü. Tasarımla bağışıklığın en temiz örneği LiveCodeBench: yalnızca modelin kesim tarihinden sonra yayınlanan problemlerde değerlendiriyor; sonuç contamination'ın tek grafikte kanıtı ("DeepSeek-Instruct performs considerably worse on problems released since September 2023 — its release date!"). Pratik kural: bir kod modelinin skoruna bakarken cutoff'undan sonraki pencereye bak.
6. Arena ELO — İnsan Tercihi Ölçmek
Statik testlerin contamination sorunu olunca alternatif insan tercihine döndü: LMSYS'in Chatbot Arena'sı (lmarena.ai; Ocak 2026'da arena.ai'ye taşındı). İki anonim modele aynı soruyu sorarsın, daha iyi cevabı seçersin, kimlikler oydan sonra açılır.
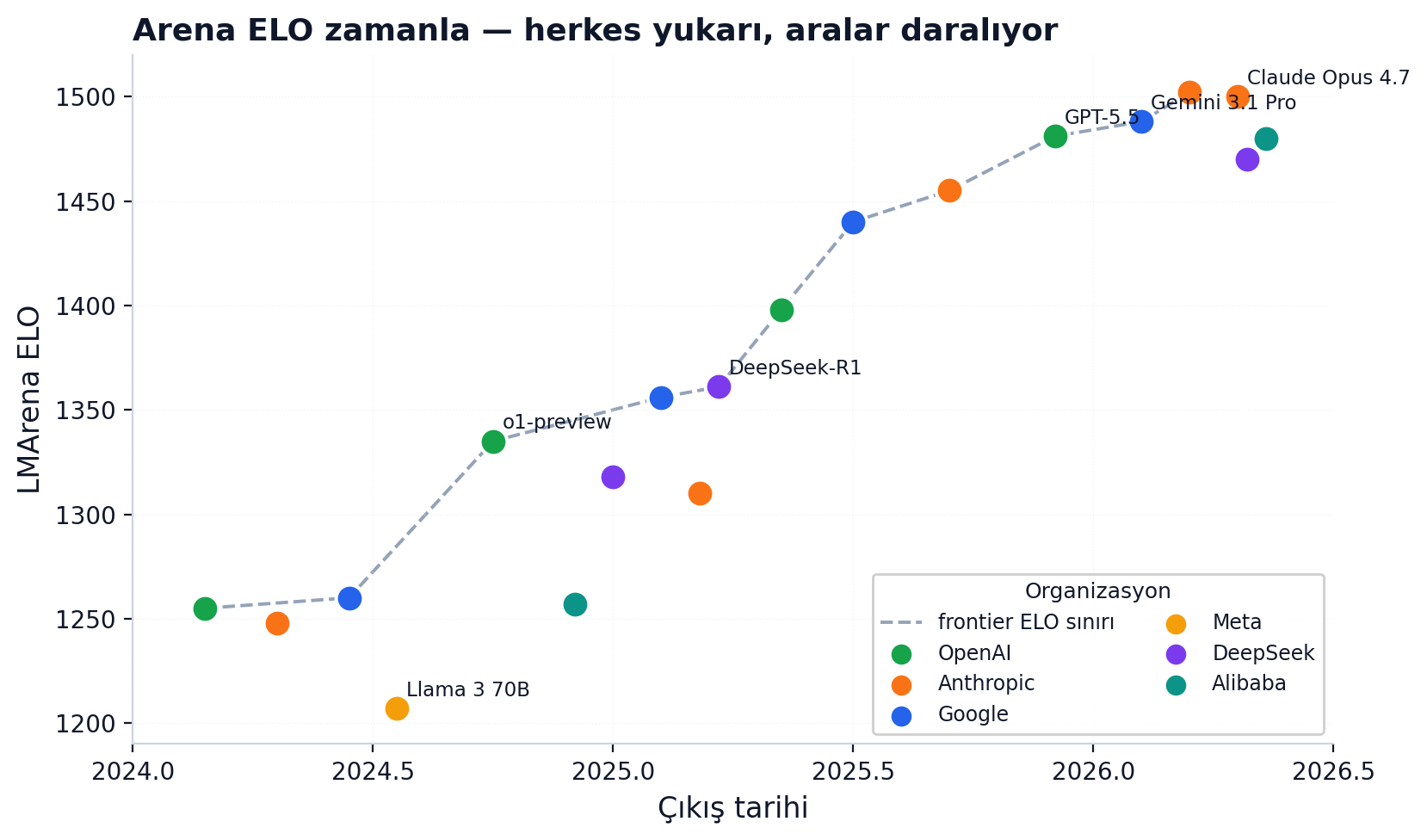
İlk myth-busting: herkes "Elo" der ama LMSYS teknik olarak Bradley-Terry kullanıyor. Daha önemlisi: bir Arena skoru tek bir sayı değil, nokta kestirimi + güven aralığıdır. İki modelin aralıkları çakışıyorsa "1. vs 2." farkı istatistiksel olarak anlamsız olabilir — sıraya değil, aralığa bak. İkinci sorun stil: LMSYS'in kendi "style control" analizi itiraf ediyor, uzun ve markdown'lı cevaplar daha çok oy alıyor; uzunluk-biçim kontrol edilince sıralama değişiyor ("GPT-4o-mini and Grok-2-mini drop below most frontier models, and Claude 3.5 Sonnet, Opus, and Llama-3.1-405B rise substantially"). İnsan, kendinden akıllı iki cevabı yargılayamayınca yüzeysel sinyallere düşüyor.
En sert eleştiri 2025'ten, Goodhart epigrafıyla açılan "The Leaderboard Illusion": Meta'nın Llama-4 öncesi gizlice 27 varyant test ettiği, Google ve OpenAI'nin Arena verisinin ~%19-20'sine eriştiği, ekstra veriyle dağılımda %112'ye varan göreli kazanç sağlandığı tespit edildi. (LMSYS itiraz etti, tartışma sürüyor.)
7. Çok-Dillilik ve Türkçe — Skorlar Hangi Dilde?
İngilizce benchmark'lar dünyanın geri kalanını ölçmüyor. En çok atıf alan çok-dilli reasoning testi MGSM bile Türkçe içermiyor — Türkçe-özel değerlendirme ihtiyacının en sade kanıtı.
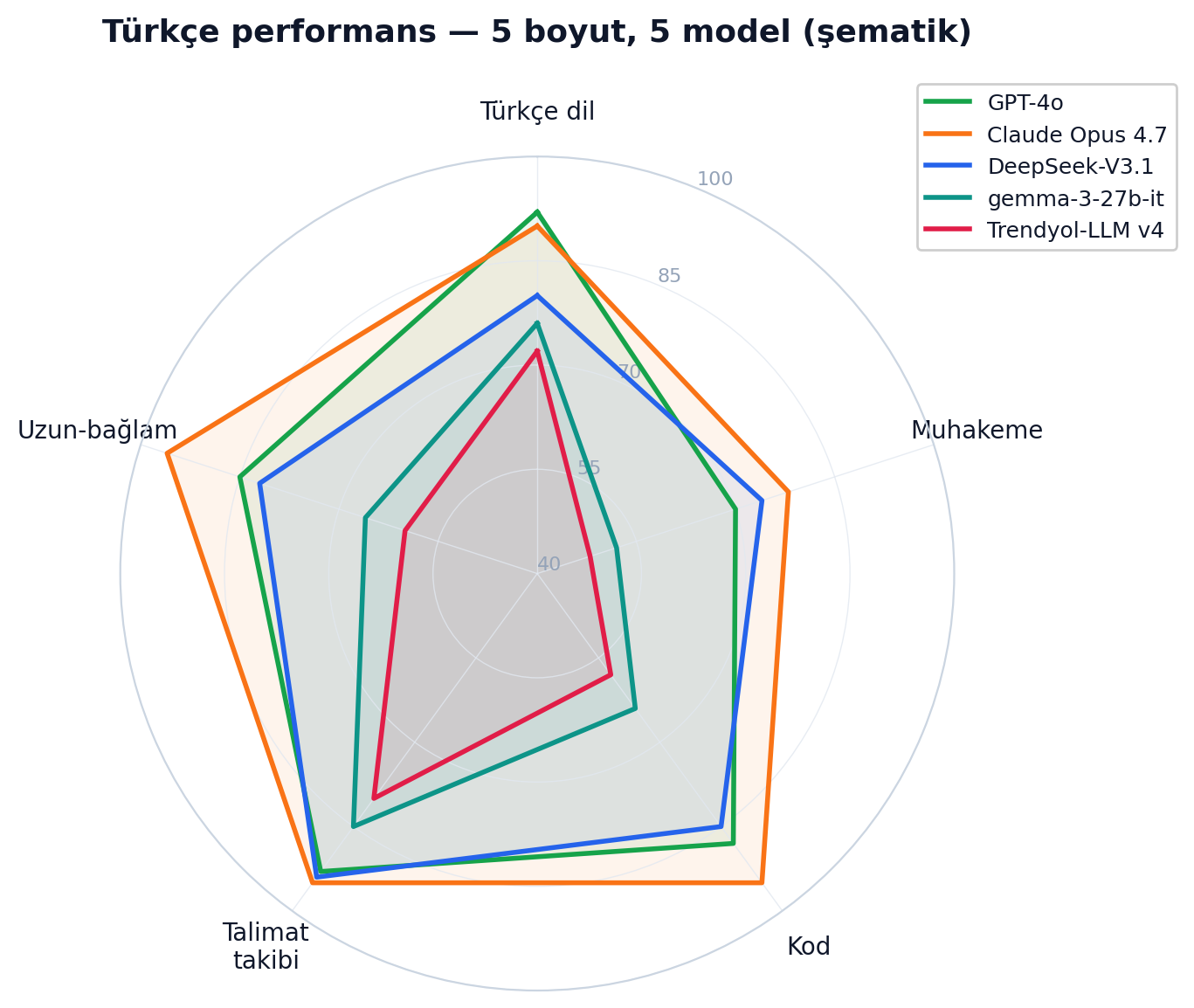
Son iki yılda native-yazılmış (çeviri değil) Türkçe benchmark'lar çıktı: TurkishMMLU (Yüksel, Köksal ve ekibi, 2024) lise müfredatından 10.000+ soruyla ilk native Türkçe MMLU'yu kurdu (otomatik çeviri "error-prone and potentially introduces culturally biased questions" olduğu için); en iyi model GPT-4o %83.1, ama matematik tüm modellerde en zayıf kategori. TR-MMLU (Bayram ve ekibi, 2025) gerçek sınavları kullandı (TUS, KPSS, AÖF); TurkBench (SIGTURK 2026) 21 alt-görev, 8.151 örnek.
İki ders. Birincisi, Türkçe-promptlu matematik herkeste çöküyor — radarın "Muhakeme" ekseninin neden içeri göçtüğü bu. İkincisi ve daha şaşırtıcı: Türkçe fine-tune otomatik üstünlük getirmiyor. TurkBench'te Türkçe-adapte gemma-3-12b-TR (%71.2), taban gemma-3-12b-it (%71.0) ile başabaş; Türkçe-özel küçük modeller (Kumru-2B %27.3) genel-amaçlı büyüklerin çok gerisinde. Taban-model ölçeği dil-adaptasyonunu yeniyor — Trendyol-LLM de LLaMA2'den Qwen2.5 tabanına geçerek bunu doğruladı.
8. Reasoning Paradigması — Aynı Modelden Farklı Cevaplar
2022'den itibaren bir dizi prompt tekniği, modelin skorunu eğitime dokunmadan değiştirdi — hepsi inference anında.
Chain-of-Thought (Wei 2022): cevaptan önce ara adımları yazdır; PaLM 540B'de GSM8K'yı sadece prompt biçimiyle ~%17'den ~%57'ye çıkardı. Yani iki makale "GSM8K skoru" diye 40 puan farklı sayı verebilir. Self-consistency (Wang 2022): N farklı zincir üret, çoğunluk oyunu al. (Notasyon, hızlıca: pass@1 = tek deneme; pass@k = k denemeden en az biri doğru; cons@k = k örneğin çoğunluk oyu; best-of-n = n örneği bir puanlayıcıyla yeniden sıralayıp en iyisini seçmek. Üçü de compute karşılığında skoru yükseltir.)
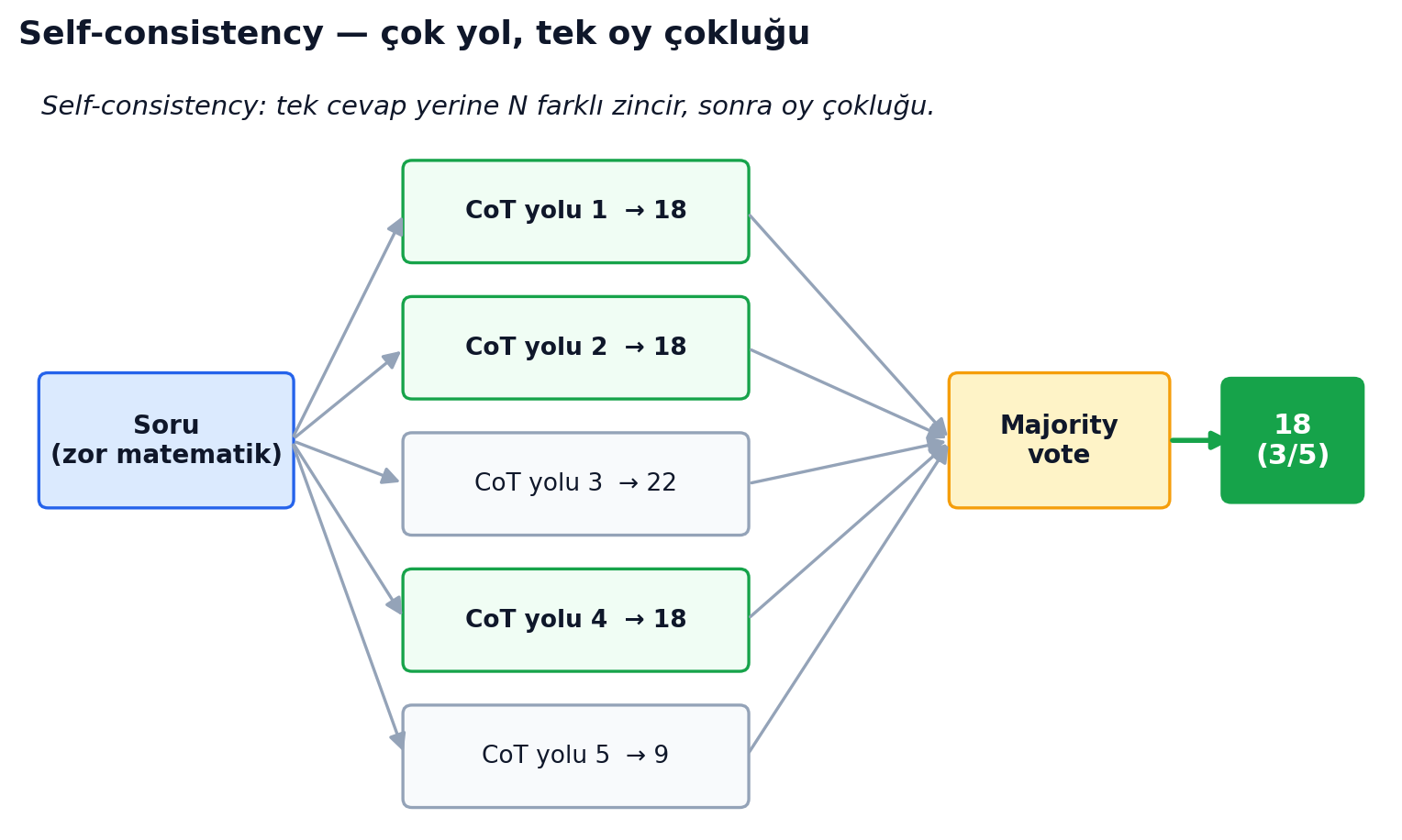
GSM8K'da +%17.9 kazandırdı, ek eğitim olmadan — ama "cons@64" etiketli skor, pass@1'in 64 katı compute harcadı; N, sonucun bir parçası. Tree of Thoughts (Yao 2023) bunu ağaç aramasına çevirdi: Game-of-24'te aynı GPT-4 CoT ile %4, ToT ile %74 — yetmiş puanlık fark modelden değil, arama stratejisinden. ReAct (Yao 2022) akıl yürütmeyi araç kullanımıyla iç içe geçirdi; Lightman ve ekibinin "Let's Verify Step by Step" çalışması (2023) ödülü her adıma verip (process reward) MATH alt-kümesinde %78'e ulaştı. Ortak tema: aynı ağırlıklar, farklı inference ayarı, bambaşka skor. "Modelin skoru" bir skaler değil; inference bütçesi üzerinde bir eğri.
9. Test-Time Compute — "Daha Çok Düşün, Daha Çok Çöz"
2024 sonunda OpenAI o1 ile bu eğri resmîleşti. Tek bir cümle bütün benchmark okumayı değiştiriyor — aynı modelin AIME 2024 skoru:
"o1 averaged 74% (11.1/15) with a single sample per problem, 83% (12.5/15) with consensus among 64 samples, and 93% (13.9/15) when re-ranking 1000 samples with a learned scoring function."
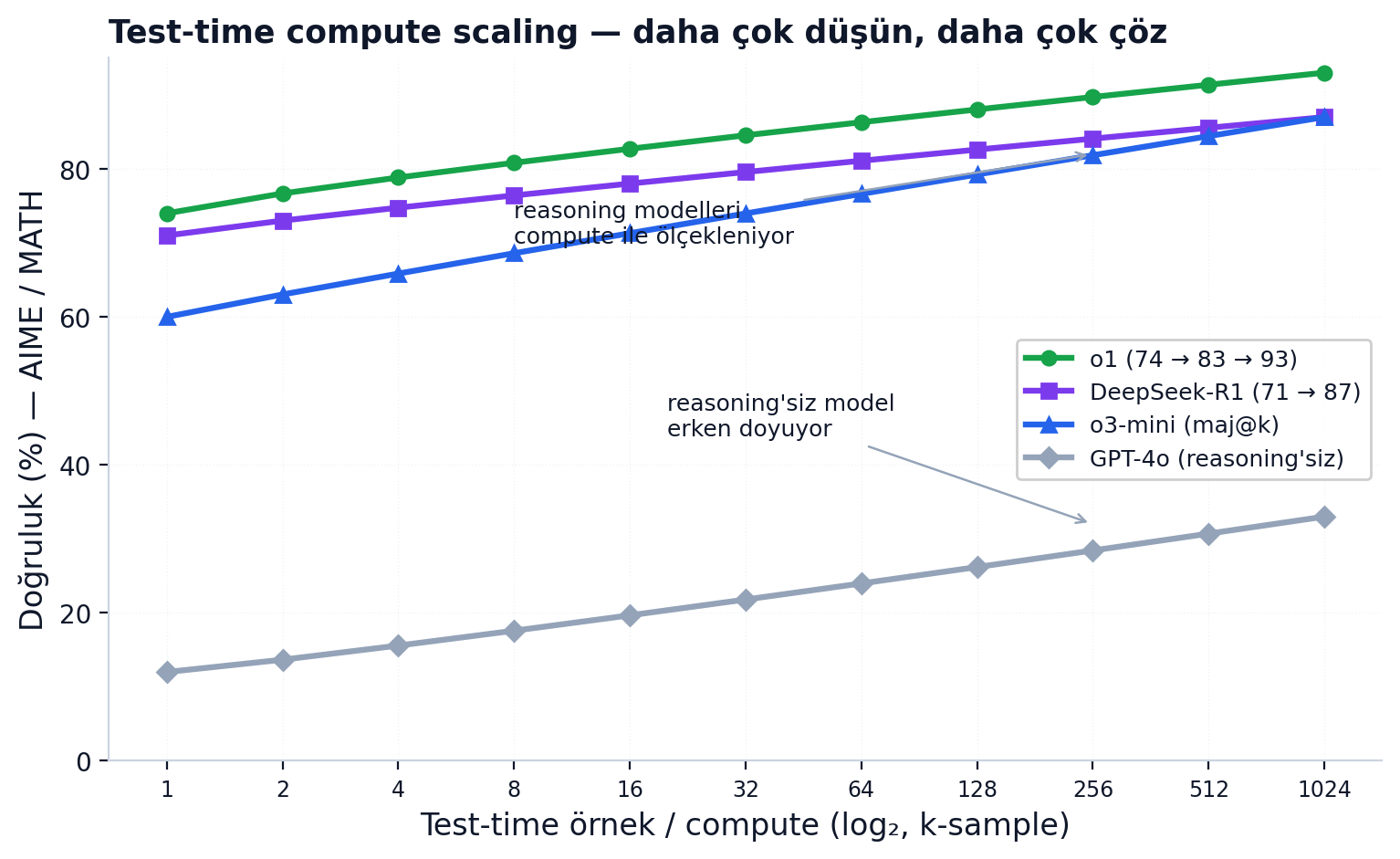
"o1 AIME'de %93" ve "o1 AIME'de %74" ikisi de doğru ve aynı modeli anlatıyor — fark sadece inference compute. Üstelik bu testler küçük: AIME yalnızca 15 soru (I+II ile 30), GPQA Diamond 198; AIME'de tek soru ≈ %6.7 demek, yani "%93 vs %87" çoğu zaman bir-iki soruluk bir fark — yani gürültü. Doymuş GSM8K'daki etiket-gürültüsü dersi (2. bölüm) küçük reasoning setlerinde de aynen geçerli. DeepSeek-R1 bunun açık-kaynak kanıtı: pure-RL (GRPO) ile AIME pass@1'i %15.6'dan %71'e, çoğunluk oyuyla %86.7'ye çıkardı; "düşünme süresini" uzatma ("aha moment") OpenAI'ye özel değil, RL-eğitimli reasoning modellerinin genel özelliği.
Asıl mesele compute'un bedeli. o3'ün ARC-AGI atılımı bunu çıplak gösteriyor: yüksek-verim modunda %75.7, görev başına ~$26 (ARC-AGI-Pub'ın $10.000/görev sınırı içinde kaldığı için public board'da 1. sıra). Düşük-verim modu (172× compute, görev başına 1.024 örnek) skoru %87.5'e taşıdı — ama ARC bu koşu için temiz bir "görev başına" rakam yayınlamaktan bilerek kaçındı; verdiği tek somut sayı ~$456.000'lık toplam faturaydı. Üstelik tahmin sabit de değil: Nisan 2025'te ARC, düşük-verim o3'ün maliyetini görev başına ~$30.000'e revize etti — bu da onu $10.000 sınırının üstüne, public leaderboard'ın dışına itti. Aynı görevleri bir insan ~$5'a çözerken. Chollet bu yüzden "efficiency (e.g., compute cost) is now a required metric" kuralını koydu: 11.8 puanlık kazanç 172× compute'a mal oluyorsa ve skorun yanında $/görev yazmıyorsa, skor yarım söylenmiştir. Ve "kim test setine erişti?" sorusunun ders kitabı vakası FrontierMath: o3'ün %25'i duyuruldu (önceki en iyi ~%2), sonra benchmark'ı yapan Epoch AI'ın OpenAI tarafından fonlandığı, OpenAI'nin problemlerin çoğuna + çözümlere eriştiği ve fonlamanın ilk makalede açıklanmadığı ortaya çıktı. Tek bir "%25", üç confounder'ı (örnek bütçesi, zorluk dağılımı, test-seti erişimi) gizledi.
10. Agent Yetenekleri — İnsan Tavanı Hâlâ Çok Yukarıda
Statik MCQ benchmark'ları doyarken ajan benchmark'larında manzara tersine: insan tavanı yüksek, model düşükten başlıyor, headroom görünür.
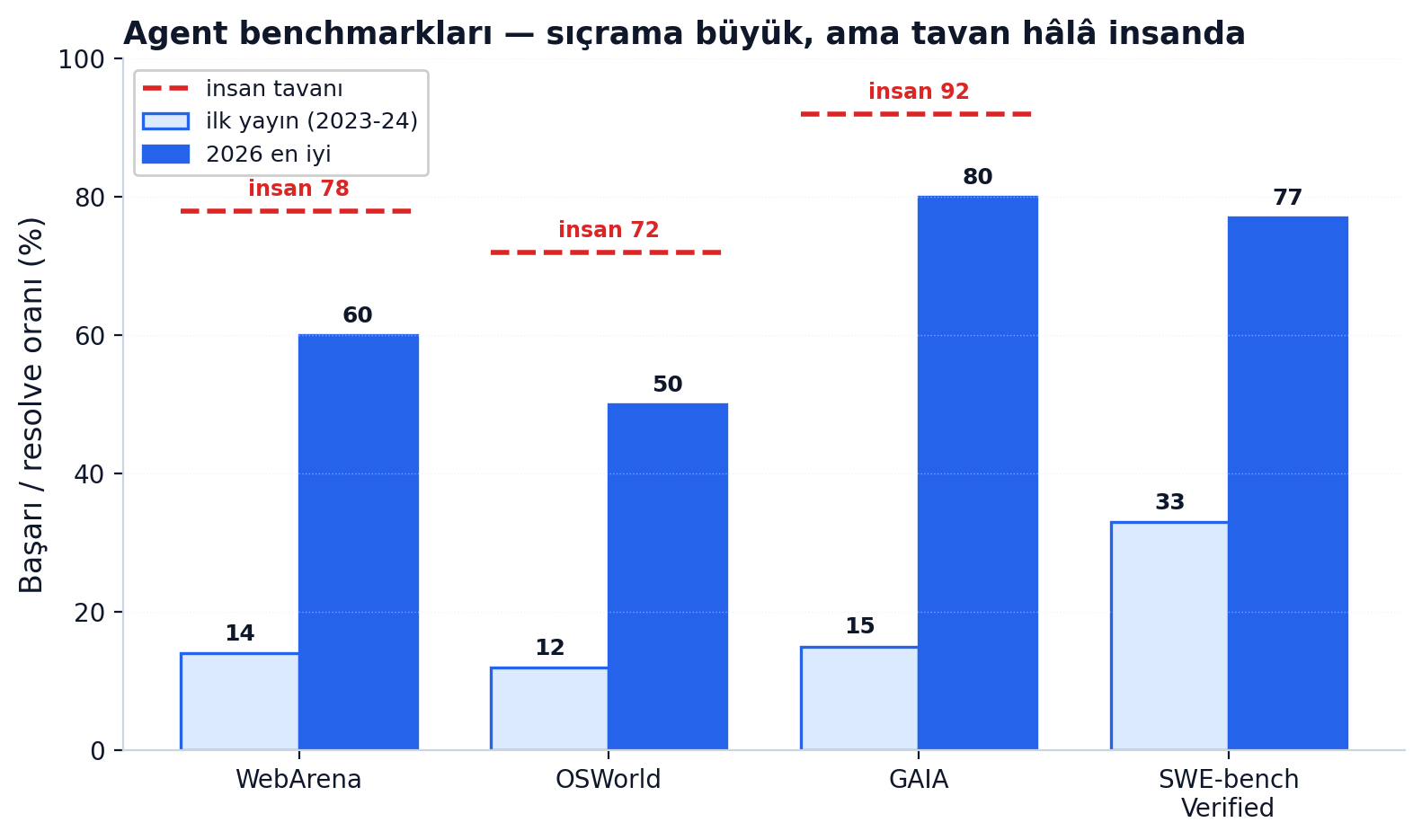
WebArena (2023): gerçekçi sitelerde görev — lansmanda en iyi GPT-4 ajanı %14.41, insan %78.24. OSWorld: insan %72.36, en iyi model %12.24. GAIA (Mialon, LeCun ve ekibi) kasıtlı tersine bir benchmark: "human respondents obtain 92% vs. 15% for GPT-4 equipped with plugins." 2026'da bu skorlar 4-6 kat arttı ama WebArena ve OSWorld'de hâlâ insan tavanının altında. Bir uyarı: ajan skorları scaffold'a aşırı bağlı — aynı model farklı sarmalayıcıyla çok farklı alır (SWE-bench'te GPT-4: kötü scaffold %2.7, iyi scaffold %28.3, ~10 kat). Dönemin standartlaşması Anthropic'in Model Context Protocol'ü (MCP, Kasım 2024) ile geldi — "AI için USB-C portu." GAIA'nın 300 cevabını gizli tutması da contamination'a karşı bir tasarım.
11. Safety Eval — Güvenlik de Metodoloji-Bağımlı
Güvenlik skorları da en az yetenek skorları kadar metodoloji-bağımlı. HarmBench (Mazeika 2024) otomatik red-teaming'i standartlaştırdı; JailbreakBench (Chao, Debenedetti, Robey 2024) jailbreak'leri tekrarlanabilir kıldı — çünkü önceki çalışmalar karşılaştırılamazdı: "there is no clear standard of practice ... existing works compute costs and success rates in incomparable ways ... numerous works are not reproducible." Yani "modelimiz %X güvenli" cümlesi de, hangi saldırı setine ve hangi tehdit modeline karşı ölçüldüğü sorulmadan okunamaz.
12. Peki Bir İddiayı Nasıl Okumalı?
Hepsini tek bir karar akışına indirgeyebiliriz. "Şu model şu benchmark'ta SOTA" cümlesini görünce sırayla sor:
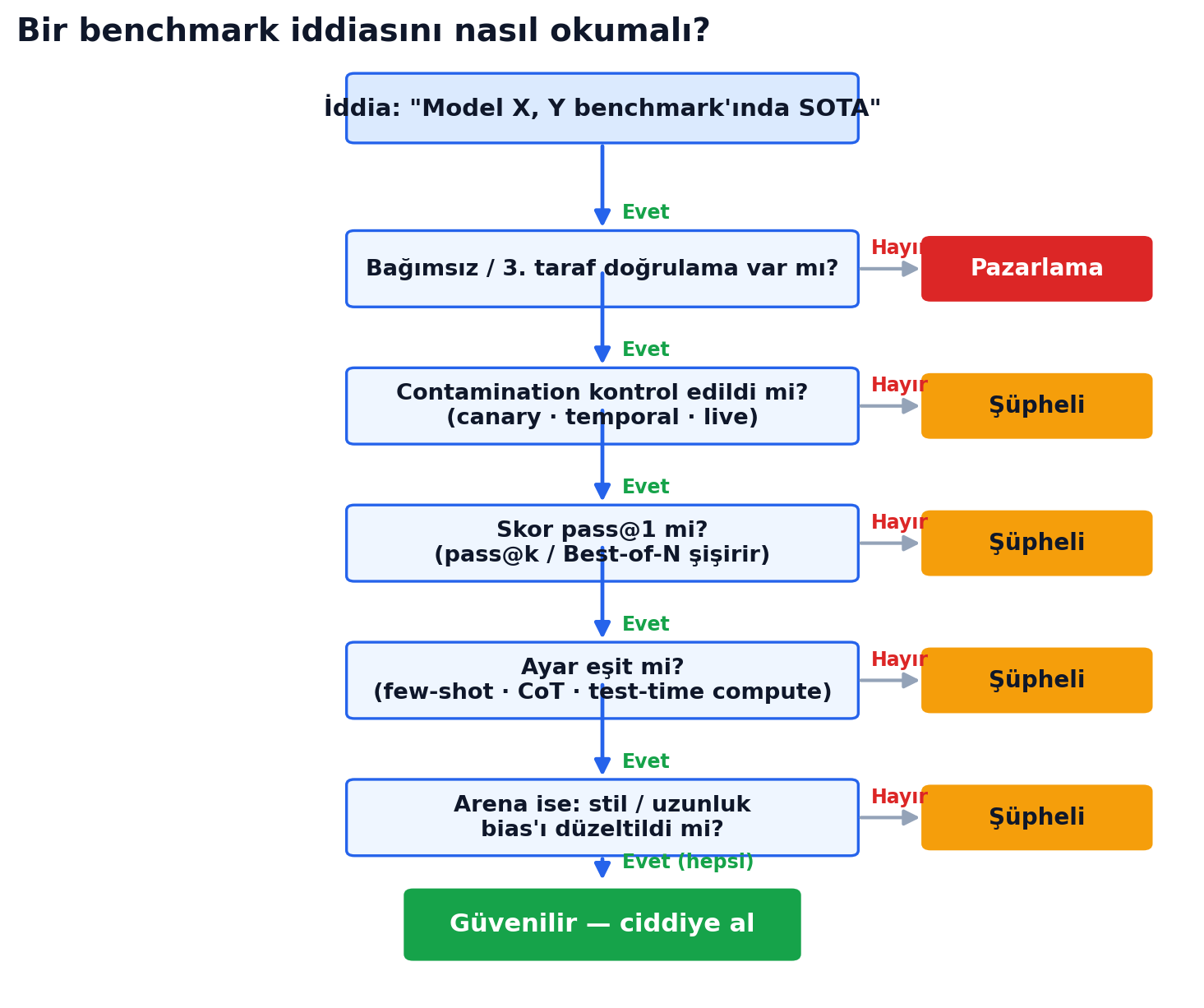
- Bağımsız doğrulama var mı? Skor modelin kendi blogundan mı, üçüncü taraf bir tablodan mı? Sadece üreticinin sayısıysa — pazarlama.
- Contamination kontrol edildi mi? Cutoff sonrası mı (LiveCodeBench), canary'li mi, private holdout mu? Değilse — şüpheli.
- Skor pass@1 mi? pass@k, cons@64, best-of-1000 sayıyı şişirir; iki sayının
@k'si aynı mı? - Ayar eşit mi? Few-shot mu, CoT var mı, ne kadar test-time compute / $ harcandı? o3'ün 172× farkını hatırla.
- Arena ise stil bias'ı düzeltildi mi? Ham Elo mu, style-controlled mı? Güven aralıkları çakışıyor mu?
Birine "hayır" çıkıyorsa skor "güvenilir" değil, "şüpheli" ya da "pazarlama" kutusuna düşer. Son bir hatırlatma — Mayıs 2026'da üç ciddi tablo aynı hafta üç farklı "en iyi" gösteriyordu: Artificial Analysis Intelligence Index'inde Claude Opus 4.8 (GPT-5.5 bir puan arkada), LMArena'da Claude Opus 4.6/4.7-thinking, llm-stats'te ise henüz yayınlanmamış (gated) Claude Mythos Preview. Hiçbiri yalan söylemiyor; farklı şeyler ölçüyorlar (agentic+akademik kompozit vs insan tercihi vs kod-ağırlıklı kompozit). "En iyi model"in cevabı "neyi ölçtüğüne bağlı"dan ibaret.
Kapanış
Açılıştaki o yeşil hücreyi okuyamadığımı söylemiştim. Artık bir grameri var: hangi benchmark (doymuş mu, frontier mı?), bağımsız mı doğrulanmış, contamination kontrol edilmiş mi, pass@1 mi pass@k mi, kaç dolar/görev, Arena ise stil düzeltilmiş mi, hangi tabloda. Bu soruların hiçbiri "model kötü" demek değil — modeller gerçekten, ölçülebilir biçimde, hızla iyileşiyor. Sadece "X, Y'yi geçti" cümlesinin, arkasındaki ölçüm bilinmeden anlam taşımadığını söylüyor.
Benchmark'lar haritadır, arazi değil. Goodhart tam burada ısırıyor: bir metrik hedef olunca iyi bir metrik olmaktan çıkıyor. Modeller benchmark'a göre optimize edildikçe benchmark gerçek yeteneği ölçmeyi bırakıyor — ve yeni, daha zoru gerekiyor. MMLU→MMLU-Pro→HLE; ARC-AGI-1→2→3; SWE-bench→Verified→Pro. Koşu bandı dönüyor ve hızlanıyor.
Kaynakça
Klasik benchmark'lar + satürasyon
- Liang et al. 2022, Holistic Evaluation of Language Models (HELM) — arxiv.org/abs/2211.09110
- Hendrycks et al. 2020, MMLU — arxiv.org/abs/2009.03300
- Wang et al. 2024, MMLU-Pro — arxiv.org/abs/2406.01574
- Cobbe et al. 2021, GSM8K / Training Verifiers — arxiv.org/abs/2110.14168 · GSM8K-Platinum — gradientscience.org/gsm8k-platinum
- Hendrycks et al. 2021, MATH — arxiv.org/abs/2103.03874
- Chen et al. 2021, HumanEval / Codex — arxiv.org/abs/2107.03374
- Zellers et al. 2019, HellaSwag — arxiv.org/abs/1905.07830
- Sakaguchi et al. 2019, WinoGrande — arxiv.org/abs/1907.10641
- Suzgun et al. 2022, BIG-Bench Hard — arxiv.org/abs/2210.09261
- Rein et al. 2023, GPQA — arxiv.org/abs/2311.12022
- Zhou et al. 2023, IFEval — arxiv.org/abs/2311.07911
- Zheng et al. 2023, MT-Bench / LLM-as-a-Judge — arxiv.org/abs/2306.05685
- Dubois et al. 2024, Length-Controlled AlpacaEval — arxiv.org/abs/2404.04475
Yeni nesil + long-context
- Phan et al. 2025, Humanity's Last Exam — arxiv.org/abs/2501.14249 · lastexam.ai
- Chollet 2019, On the Measure of Intelligence (ARC) — arxiv.org/abs/1911.01547 · ARC Prize / o3 — arcprize.org/blog/oai-o3-pub-breakthrough
- Jimenez et al. 2023, SWE-bench — arxiv.org/abs/2310.06770 · SWE-bench Verified — openai.com/index/introducing-swe-bench-verified
- Liu et al. 2023, Lost in the Middle — arxiv.org/abs/2307.03172
- Hsieh et al. 2024, RULER — arxiv.org/abs/2404.06654
- Bai et al. 2023, LongBench — arxiv.org/abs/2308.14508 · Zhang et al. 2024, ∞Bench — arxiv.org/abs/2402.13718
Arena + contamination
- Chiang et al. 2024, Chatbot Arena — arxiv.org/abs/2403.04132 · Style Control — lmsys.org/blog/2024-08-28-style-control
- Singh et al. 2025, The Leaderboard Illusion — arxiv.org/abs/2504.20879
- Sainz et al. 2023, NLP Evaluation in Trouble — aclanthology.org/2023.findings-emnlp.722
- Zhang et al. 2024, GSM1k — arxiv.org/abs/2405.00332
- Yang et al. 2023, Rephrased Samples / llm-decontaminator — arxiv.org/abs/2311.04850
- Jain et al. 2024, LiveCodeBench — arxiv.org/abs/2403.07974 · White et al. 2024, LiveBench — arxiv.org/abs/2406.19314
Reasoning + test-time compute
- Wei et al. 2022, Chain-of-Thought — arxiv.org/abs/2201.11903
- Wang et al. 2022, Self-Consistency — arxiv.org/abs/2203.11171
- Yao et al. 2023, Tree of Thoughts — arxiv.org/abs/2305.10601 · Yao et al. 2022, ReAct — arxiv.org/abs/2210.03629
- Lightman et al. 2023, Let's Verify Step by Step (PRM) — arxiv.org/abs/2305.20050
- OpenAI 2024, Learning to Reason with LLMs (o1) — openai.com/index/learning-to-reason-with-llms
- DeepSeek-AI 2025, DeepSeek-R1 — arxiv.org/abs/2501.12948
- Snell et al. 2024, Scaling Test-Time Compute — arxiv.org/abs/2408.03314
- Anthropic, Claude's extended thinking — anthropic.com/research/visible-extended-thinking
Agent + safety + multilingual + Türkçe
- Zhou et al. 2023, WebArena — arxiv.org/abs/2307.13854
- Xie et al. 2024, OSWorld — arxiv.org/abs/2404.07972
- Mialon et al. 2023, GAIA — arxiv.org/abs/2311.12983
- Anthropic 2024, Model Context Protocol — modelcontextprotocol.io · Computer use — anthropic.com/news/developing-computer-use
- Mazeika et al. 2024, HarmBench — arxiv.org/abs/2402.04249 · Chao et al. 2024, JailbreakBench — arxiv.org/abs/2404.01318
- Yüksel et al. 2024, TurkishMMLU — arxiv.org/abs/2407.12402 · Bayram et al. 2025, TR-MMLU — arxiv.org/abs/2501.00593
- TurkBench (SIGTURK 2026) — arxiv.org/abs/2601.07020 · Trendyol-LLM — huggingface.co/Trendyol
Canlı leaderboard'lar (Mayıs 2026 snapshot)
- Artificial Analysis — modeller: artificialanalysis.ai/leaderboards/models · GPQA Diamond: /evaluations/gpqa-diamond · HLE: /evaluations/humanitys-last-exam
- LMArena (artık arena.ai) · Scale HLE — labs.scale.com/leaderboard/humanitys_last_exam · llm-stats — llm-stats.com
Finis