Şu cümleyi yüksek sesle oku: "Trained on 15.6T tokens with FSDP on 16K H100, then SFT on UltraChat, then DPO on UltraFeedback, then GRPO with verifiable rewards." Llama 3.1'in Hugging Face kartının ilk satırı. Bütün kavramlar içine sıkıştırılmış, ama hiçbiri açıklanmamış — okuyan ya iki saniye duraklar, ya da bir anda anlamış gibi yapıp devam eder.
İki yıl önce bu cümleyi ilk okuduğumda kafamda hiçbir şey kıpırdamamıştı. Yapay zekanın hangi parçası bu adamı yiyor, hangi parçası modeli yiyor, hangisi para — ayırt edemiyordum. Sonra kelimeleri tek tek sözlüğe yatırdım. Her biri bir hafta sonu çıktı. Bu yazı, o sözlük çalışmasının tek dosyaya sığdırılmış hâli — sonunda cümleye geri döndüğünde her kelime ağırlığını taşıyor, daha iyisi "bu kadar mı, gerçekten?" diyebiliyorsun.
Önceki iki yazıda kavramları çevirdik (token, parametre, embedding) ve mimariyi söktük (attention, RoPE, GQA). Bu yazı üçleyi tamamlıyor: inşaat. Bir LLM eğitiminin gerçek zinciri — veri toplama, optimizer ayarı, ödül mimarisi, ve son birkaç yılın "her şey değişti" anlatısı.
Mayıs 2026 itibarıyla bir LLM eğitiminin dört evresi şu:

Her evrenin tek paragraflık özeti:
Pretraining: Trilyonlarca token üzerinde, "bir sonraki token'ı tahmin et" oyunu. Aylar süren GPU eğitimi. Llama 3.1 405B için 15.6 trilyon token, 3.8 × 10²⁵ FLOPs, 16K H100 GPU üzerinde — Meta'nın 2024 paper'ı bütün rakamları açık veriyor. Çıktı: dili biliyor ama henüz asistan olmayan bir base model.
SFT (Supervised Fine-Tuning): Base model "internet rüya görüyor" durumunda; bu rüyayı asistan davranışına çevirmek için 100K-1M kuralı talimat üzerinde mini bir fine-tune. InstructGPT (Ouyang 2022) bu pipeline'ı resmi olarak tanımlayan paper.
Preference Tuning: SFT modeli güzel cevap veriyor ama bazen güvensiz, bahaneci, döngüsel. İnsana hangi cevabı tercih ettiğini soralım, modeli ona göre ayarlayalım. RLHF (PPO) klasik yol; DPO (Rafailov 2023) son üç yılın açık-kaynak standardı; ikisinin pratik farkı dramatik.
Reasoning RL: Modeli "düşünmeye" itecek son ayar. Matematik veya kod gibi cevabın doğruluğunun otomatik kontrol edilebildiği alanlarda, GRPO (DeepSeek 2024-25) ile pure-RL eğitim. R1-Zero'nun meşhur "aha anı" bu evrede çıkıyor.
Önemli sezgi: pretraining "ne biliyor"u, SFT "nasıl konuşur"u, preference "neyi söylemez"i, reasoning RL "nasıl düşünür"ü öğretir. Her evre bir öncekinin üstüne yazar — parametre sayısı değişmez, sadece ağırlıklar yeniden şekillenir.
> Kapsam notu: Bu evrelerin arasında, bu yazıda kasıtlı atladığım bir ara adım var: uzun-bağlam genişletme (Llama 3'ün 8K → 128K context extension'ı gibi), genelde pretraining'in sonuyla post-training arasında ayrı bir faz olarak koşulur. Tek başına bir yazıyı hak ediyor; burada zinciri kısa tutuyorum.
Hadi tek tek girelim.
1. Pretraining — Veri Cehennemi
Bütün uygulamalı yapay zeka tarihinde, en az glamour'a sahip iş bu evrede. İşin %80'i veri temizliği, %15'i mühendislik, %5'i araştırma. Ve maliyetin de %80'i burada.
Veriyi nereden topluyorsun
Modern bir LLM'in pretraining karışımı kabaca üç gruba ayrılır:
- Web: Common Crawl. Aylık ~3 milyar URL'lik snapshot'lar; ham boyut petabyte. Bu kadarını veriye dönüştürmek başlı başına bir endüstri.
- Yapılandırılmış kaynaklar: GitHub (kod), ArXiv (bilim), Stack Exchange (soru-cevap), Wikipedia, kitaplar, lisanslı içerik.
- Sentetik veri: Yeni standardın yarıdan çoğu. Phi-4 raporu açık söylüyor: 50 farklı sentetik dataset tipi, toplam ~400 milyar eşsiz sentetik token üretildi; upsampling'le birlikte bu sentetik veri ~10T token'lik pretraining karışımının ~%40'ını oluşturuyor. (İki sayı çelişmiyor: 400B = üretilen benzersiz token sayısı, %40 = tekrar payıyla eğitim karışımındaki oran.)
HuggingFace'in 2024'te yayınladığı FineWeb bu çağın açık-kaynak referansı: 15 trilyon token, 96 Common Crawl snapshot'tan. FineWeb-Edu (eğitsel kalite classifier ile filtrelenmiş) ise 1.3 trilyon token. Penedo et al. paper'ı filtrenin ampirik olarak tasarlandığını söylüyor — her aşamada 28B token ablation modeli (1.8B parametre) eğitilip karşılaştırılıyor. Sezgiyle değil, ölçümle.
Filtreleme pipeline'ı
FineWeb'in akışını yan yana yazdığında neyi temizlediğin ortaya çıkıyor:
- Text extraction: trafilatura ile WARC dosyalarından. WET verisi (Common Crawl'ın hazır text dump'ı) daha kötü.
- Base filtering: URL blocklist, dil tespiti (fastText, İngilizce > 0.65), Gopher kalite filtreleri, tekrar filtreleri. Bu adımdan sonra ~36T token kalıyor.
- Deduplication: MinHash, 5-gram, 112 hash function, 14 bucket × 8 hash/bucket, ~%75 benzerlik eşiği. Aynı bucket'ta 8 MinHash'i çakışan dokümanlar duplicate sayılıyor.
- Per-snapshot dedup — snapshot-arası global dedup yapılmıyor. Çünkü global dedup eski snapshot'larda kalan veriyi düşük kaliteye sürüklüyor. Penedo et al. bunu somut bir ablasyonla gösterdi: eski bir snapshot tek başına ele alındığında, global dedup sonrası elde kalan %10'luk veri, atılan %90'dan daha düşük kaliteliydi — yani agresif global dedup kaliteyi düşürüyordu.
- Heuristic filters (50+ aday'dan 3 tanesi seçilmiş): terminal punctuation oranı, tekrar eden satır oranı, kısa satır oranı.
Bu listede yapay zeka yok. KenLM, fastText, MinHash — bunların hepsi 2010'lar teknolojisi. Modern LLM'lerin verisi, modern olmayan araçlarla temizleniyor. Bu açıdan, "veri mühendisliği" "ML mühendisliği"nden ayrı bir disiplin.
Veri karışımı
Aynı 10-15 trilyon token üzerinde eğitilse bile, karışım modelin karakterini belirler. Üç farklı strateji:
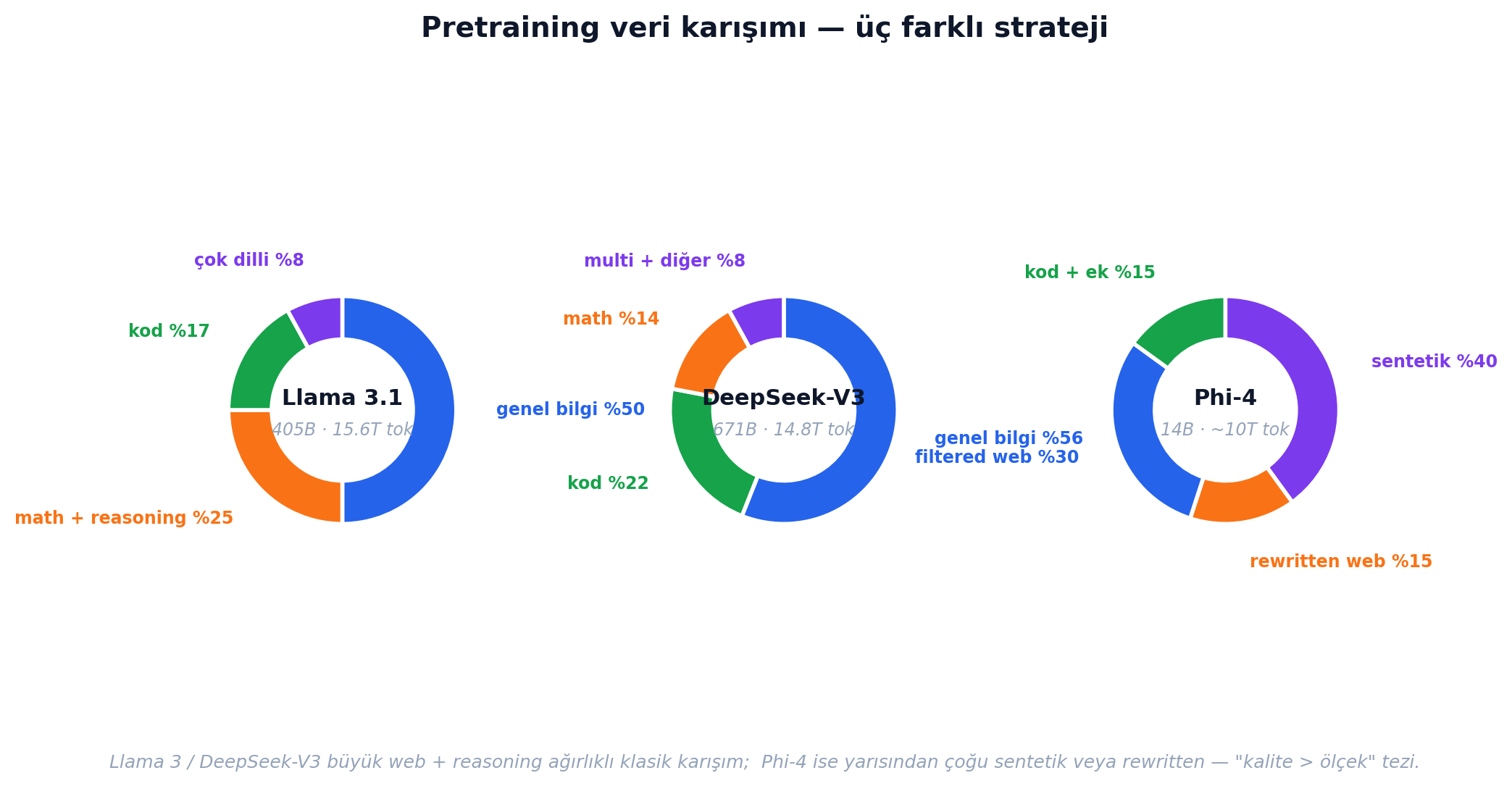
- Llama 3.1 405B (Meta paper, §3.1.3): %50 genel bilgi, %25 matematik + reasoning, %17 kod, %8 çok dilli. 15.6T token.
- DeepSeek-V3: 14.8T token, ağırlık benzer ama kod payı %22'ye çıkmış — DeepSeek'in coding karakteri buradan.
- Phi-4: 14B dense, ~10T token, ama bunun ~%40'ı sentetik. "Quality over scale" tezi paper'ın açılış cümlesi.
Phi-4'ün cüretkâr hamlesi MMLU 84.8, MATH 80.4, HumanEval 82.6 ile karşılık buldu — 14 milyar parametreyle 70B-sınıfı eval skorları. Microsoft'un 2024 raporu sonucu açık söylüyor: yalnızca sentetik veriyle eğitilen modeller bilgi-yoğun benchmark'larda geri kaldı ve daha çok halüsinasyon üretti. Yani sentetik tek başına çözüm değil — karışıma giren bir bileşen.
Chinchilla — token bütçesi de parametreye sığar mı?
2022'de DeepMind'ın Chinchilla paper'ı (Hoffmann et al.) o güne kadarki tüm ölçek anlayışını ters çevirdi. Önceki büyük modeller (GPT-3, Gopher) parametre kadar veriyle eğitilmemişti. Pratik kural: her parametre için ~20 eğitim token'ı.
Chinchilla 70B → 1.4T token = 20×. Gopher 280B → 300B token = ~1×. Aynı compute bütçesinde, Chinchilla MMLU 67.5 ile Gopher'ı 7 puan geçti. Paper'ın açılış cümlesi tüm sektörü utandırdı: "current large language models are significantly undertrained."
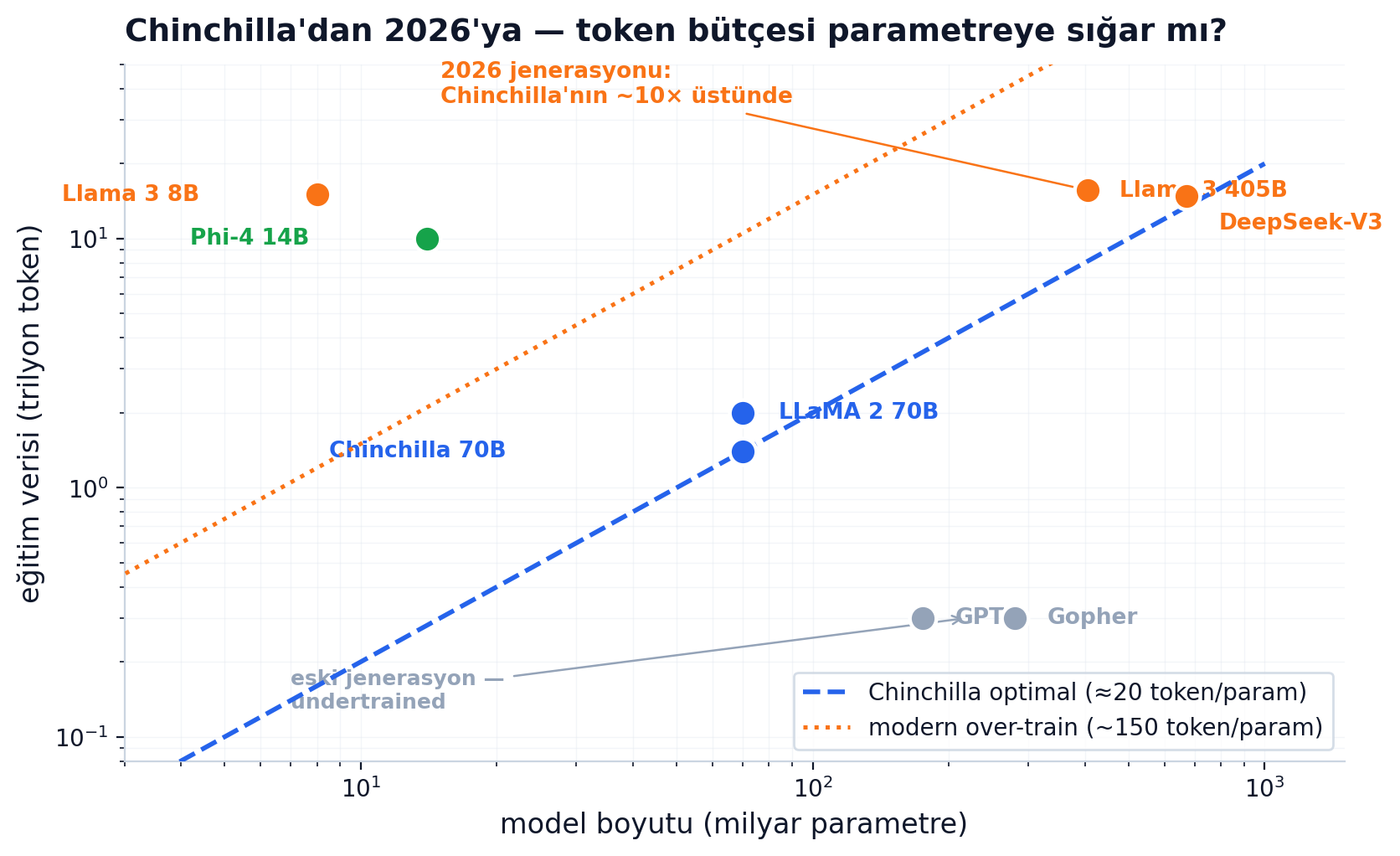
> Dense vs MoE — neden iki ayrı parametre sayısı var? > > Llama gibi dense modellerde her token bütün parametrelerden geçer; "405B" hem bellek hem compute demektir, ikisi aynı sayı. DeepSeek-V3 ise Mixture-of-Experts (MoE): 671B toplam parametrenin token başına yalnız ~37B'si aktif — bir router her token'ı küçük bir uzman alt-kümesine yönlendiriyor. Sonuç: bellek 671B'ye göre planlanır, ama compute (ve dolayısıyla Chinchilla'nın token/parametre oranı) aktif parametre üzerinden okunur. Bir MoE modelini dense modellerle aynı tabloya koyarken bu yüzden aktif parametre kullanmak gerekir.
2026'da iş daha da değişti. Llama 3.1 405B → 15.6T token ≈ 38 token / parametre. DeepSeek-V3 (MoE; ~37B aktif) → 14.8T token ≈ 400 token / aktif-parametre — toplam 671B üzerinden bakarsan 22 çıkar, ama o sayı yanıltıcı; compute açısından anlamlı oran aktif parametre üzerinden. Llama 3 8B → 15T token = 1875 token / parametre. Hangisi doğru?
Cevap: "compute-optimal" Chinchilla'nın resmidir, "inference-optimal" 2026'nın resmidir. Çünkü modeli bir kez eğitiyorsun ama trilyonlarca kez inference koşturuyorsun. Eğitim sırasında biraz daha fazla data harcayıp daha küçük model üretmek, üretim sırasında her sorguda kazanılan saniyelerle geri ödüyor. "Over-train" diye anılan bu strateji bugün 8B-30B sınıfında varsayılan. Aktif parametreyle bakınca DeepSeek-V3 de (400 token/aktif-param) tam bu over-train tarafında — küçük dense modeller gibi, Chinchilla-optimal bir nokta değil.
Phi-4 14B + 10T token ≈ 715 token / parametre — bu sayı 2022'de "delilik" sayılırdı; 2026'da "kalite > ölçek"in matematiksel ifadesi.
Sentetik veri çağı — ve "Model Collapse"
Sentetik veriyi savunmak kolay (Phi-4 kadar konuşur). Karşıt argüman da güçlü: Shumailov et al. 2023 ve Nature 2024 paper'ı Model Collapse olgusunu kanıtladı: modelin kendi ürettiği içerikle eğitmek sonuçta geri-dönülmez kusurlar yaratıyor — orijinal içerik dağılımının kuyrukları kayboluyor.
Yani: dağılımın "kuyrukları" (nadir, sürpriz pattern'ler) kayboluyor. Fotokopinin fotokopisi: çıktılar giderek genelleşir, kenarlar törpülenir.
Communications of the ACM, Mart 2026'da "Model Collapse Is Already Happening, We Just Pretend It Isn't" başlıklı bir blog yazısı yayınladı. Web içeriğinin %50'sinden fazlasının AI üretimi olduğu tahmin ediliyor. Cloudflare Radar'ın verisine göre Anthropic'in crawler'ı (ClaudeBot) için crawl-to-refer oranı Temmuz 2025'te ~38,000:1 — yani ~38 bin sayfa indirilip bir tane referans veriliyor (Ocak 2025'teki ~286,000:1'den düşmüş ama hâlâ açık ara en yüksek). Sonuç: sentetik dolaşımı veriyi yiyor.
Önemli ayrım: replace (sentetiği gerçeğin yerine koy → çöküş kaçınılmaz) vs accumulate (sentetiği gerçeğe ekle → çöküş kaçınılabilir). Phi-4 başarısı accumulate stratejisinde; pure-replace cyclical training'de model çöker.
> Bu konuda Karpathy'nin gözlemi sezgisel: bir model hiçbir zaman kusursuz olmadığından, kendi çıktısıyla her yeniden eğitildiğinde dağılımdan biraz daha bilgi sızdırır — kayıp birikir.
Sektör 2026'da iki gerçeği birlikte tutmaya çalışıyor: sentetik veri büyümeyi sürdürüyor, ama gerçek insan verisinin değeri sürekli artıyor. "Towards AI"ın Mart 2026 yazısının özeti: bugün her ciddi AI laboratuvarında dönen tartışma mimari ya da compute bütçesi değil — veri.
2. Loss, Optimizer ve Sayısal Hassasiyet — Motorun İçi
Veri var, model mimarisi (transformer) var. Eğitim cümlesi şu: "modeli, eğitim verisi üzerinde cross-entropy loss'u minimize edecek şekilde gradient descent ile güncelle." Üç kelimelik motor.
Cross-entropy & perplexity
Her token'da modelin tahmini bir olasılık dağılımı (vocab boyutu kadar). Doğru token için modelin verdiği olasılık p. Cross-entropy loss = -log(p). Bütün dataset üzerinde ortalama.
Perplexity = exp(loss). Pratik tercüme: modelin "kafası bir token'ı tahmin ederken kaç eşit-olasılıkçı seçenek arasında karar veriyor gibi"? Loss 2.5 → perplexity ~12. Yani model her token'da sanki 12 seçenek arasında atış yapıyor. Loss 1.5 → perplexity ~4.5. Daha az şaşkınlık, daha iyi model.
AdamW: SGD'nin moderni
LLM eğitiminin %99'unda kullanılan optimizer: AdamW. Momentum (geçmiş gradient'ları hatırla) + adaptive LR (her parametre için ayrı ölçek) + decoupled weight decay (L2 regularization'ı gradient'tan ayır).
Pratik default'lar (GPT-3'ten beri büyük LM eğitiminde yerleşik değerler): β1=0.9, β2=0.95, weight_decay=0.1. Buradaki β2=0.95 Adam'ın standart 0.999'u değil — büyük-batch LM eğitiminde 0.95 daha kararlı; bu değer GPT-3 pretraining'inden (Brown 2020) geliyor, InstructGPT'ye özel bir seçim değil. SFT gibi fine-tune adımlarında LR düşük tutulur (~1e-5); pretraining'de daha yüksek (3e-4 - 6e-4 civarı, batch'a göre) — Phi-4 raporu peak LR=0.0003, weight decay=0.1.
Learning rate schedule — cosine vs WSD
Önceki standart cosine decay: warmup (LR'yi sıfırdan zirvelere çıkar) sonra cosine eğrisiyle minimuma in. Sorun: cycle'ı önceden sabitlemen gerek, ortada durup "şimdi daha çok train edeyim" diyemiyorsun.
WSD (Warmup-Stable-Decay), Nisan 2024'te MiniCPM paper'ıyla popülerleşti. Üç faz: warmup → uzun, sabit yüksek LR → final decay. Stable phase'in uzunluğunu istediğin kadar uzatabiliyorsun, sonra "tamam yeter" deyip son decay'ı başlatıyorsun. Continuous training için ideal. MiniCPM "data-model scaling law'u extensive retraining olmadan çıkardık" diye iddia ediyor — WSD bu işin temeli.
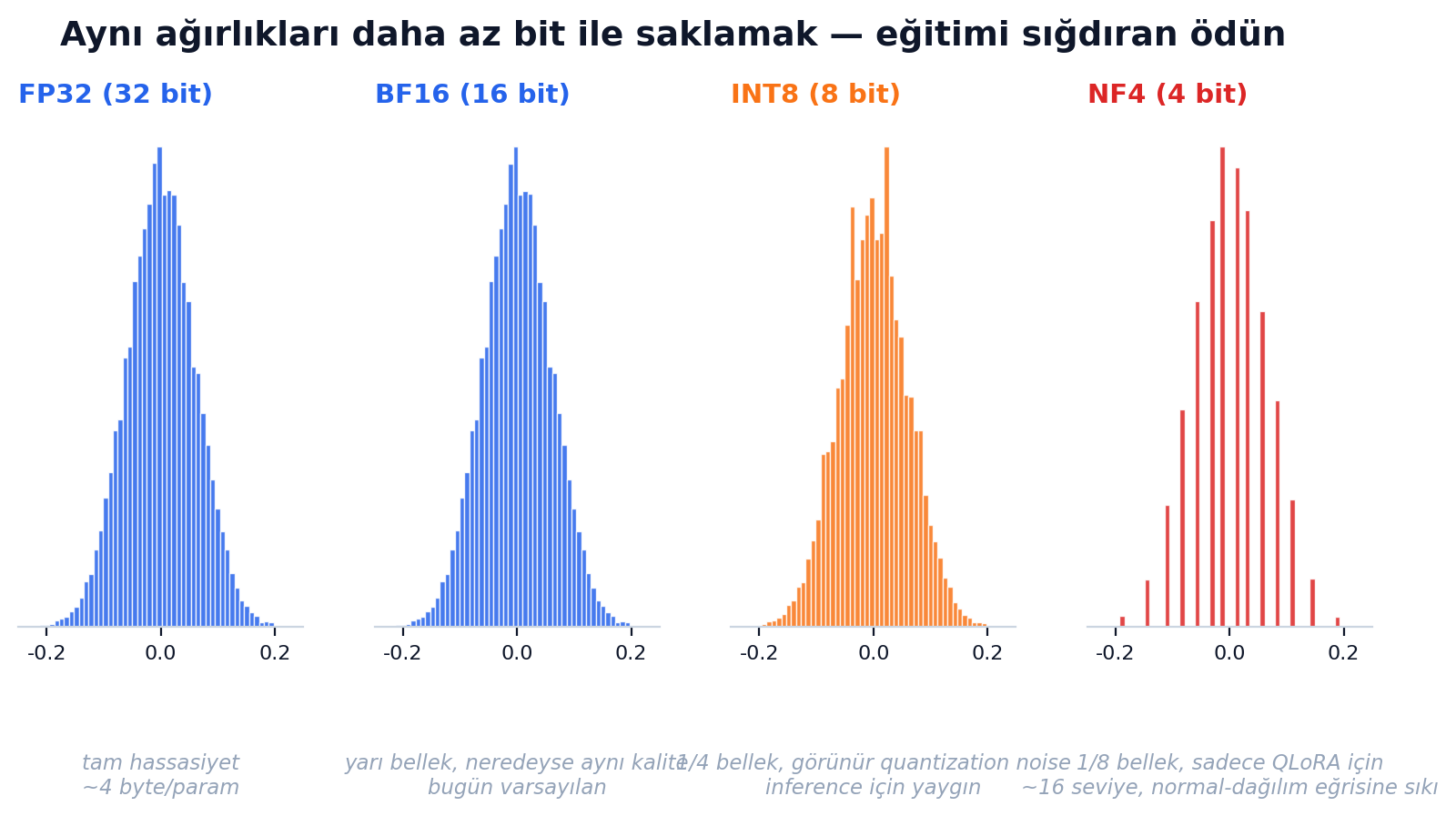
Mixed precision — FP32'den FP8'e yolculuk
Eğitim sayıları gerçekten ne hassasiyette tutuluyor?
- FP32 (32 bit): klasik. Her ağırlık 4 byte. 7B model → 28 GB sadece ağırlık.
- BF16 (16 bit, "brain float"): forward + backward'da kullanılır, master copy FP32'de. Tipik mixed precision recipe'i. Bellek yarıya iner, kalite neredeyse değişmez. Bugün varsayılan.
- FP8: Hopper (H100) ve Blackwell GPU'larda donanım desteği var. NVIDIA Transformer Engine "E4M3 forward + E5M2 backward" hibridini standartlaştırdı.
FP8 artık egzotik değil. Microsoft'un FP8-LM paper'ı (Ekim 2023) GPT-175B'yi H100'de eğitirken FP8 mixed-precision çerçevesinin gerçek bellek kullanımını %39 düşürdüğünü ve yaygın BF16 çerçevesinden %75 daha hızlı koştuğunu raporladı. DeepSeek-V3 (Aralık 2024) ise large-scale eğitimde FP8 mixed-precision'ı production'da kullanan ilk büyük açık modeldi — "tamamı FP8" değil; hassas operasyonlar (bazı GEMM'ler, master weight, optimizer state'in bir kısmı) daha yüksek hassasiyette tutulur. Yine de mühendislik başarısı çarpıcı: 671B parametreyi 2.788M H800 GPU saatinde, hiç geri-dönülmez loss spike yaşamadan ve hiç rollback yapmadan eğittiler.
Blackwell GPU'larda MXFP8 (microscaling FP8) ve NVFP4 (4-bit) eğitim desteği geldi. 2026'da büyük açık model eğitimi pratiğinde FP8 + BF16 master + FSDP stack'i artık fiilen standart.
Loss spike'lar — gerçekte ne oluyor
İdealdeki loss eğrisi düzgün iner. Gerçekte:
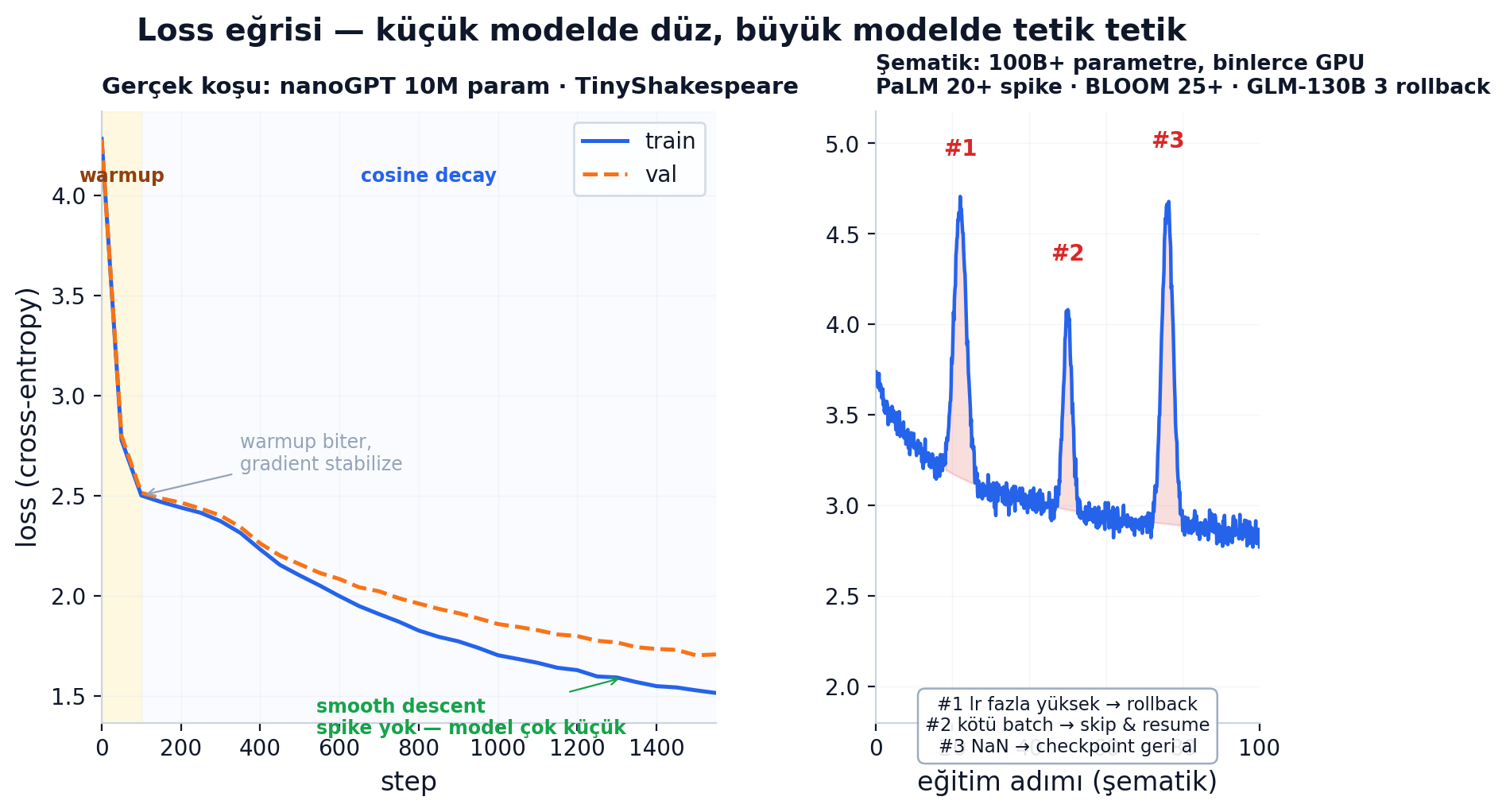
Sol panelde yukarıda gerçek bir nanoGPT koşusunun loss'u. 10M parametre, TinyShakespeare, ~1500 step. Warmup → cosine decay. Spike yok. Çünkü 10M parametre.
Sağ panel şematik. PaLM (540B, Google) eğitim sırasında "12 ila 20 arası" spike yaşadı (paper raporu). BLOOM (176B, BigScience) 25+. GLM-130B (Tsinghua) 3 emergency rollback yapmak zorunda kaldı. Sebep çeşitli: çok yüksek LR, kötü batch (toxik veri bombası), sayısal taşma, "death by NaN."
Pratik müdahale: önceki checkpoint'e geri dön, problematik batch'i atla, LR'yi düşür, devam et. DeepSeek-V3'ün "no rollbacks" iddiası bu sektörel deneyime kıyasla ciddi bir mühendislik başarısı.
Llama 3 paper'ı 405B'nin 54 günlük eğitim koşusunda beklenmedik interrupt'ların %78'inin donanım kaynaklı olduğunu söylüyor. Yani bilgisayar yandı, GPU çöktü, network koptu — loss spike'lardan önce gelen problem. Tablo 5'te detay var: 419 beklenmedik interrupt; en büyük iki kalem 148 GPU arızası (%30.1) ve 72 HBM3 bellek hatası (%17.2) — ikisi ayrı satır, yani "GPU + HBM3" kalemi tek başına 220 interrupt eder.
Distributed training — DP, TP, PP, FSDP
Tek GPU'da 7B model BF16 olarak 14 GB ağırlık + ek bellek = 20 GB+ → yüksek-end consumer GPU'ya zar zor sığar. 70B'yi tek GPU'da eğitemezsin. Dağıtmak şart.

- DP (Data Parallel): Her GPU modelin tam kopyasını tutar. Veri parçalanır, gradient all-reduce ile birleşir. Basit ama 4× redundant bellek.
- TP (Tensor Parallel): Her layer'ın matrisi sütun veya satır olarak GPU'lar arası bölünür. Megatron-LM klasik implementasyon.
- PP (Pipeline Parallel): Model katmanlara dilimlenir, GPU 0 katman 1-20'yi, GPU 1 katman 21-40'ı tutar. Forward/backward stage-by-stage. Pipeline bubble sorunu ile yaşa.
- FSDP / ZeRO-3: Microsoft'un ZeRO paper'ının (Rajbhandari 2020) PyTorch'a native gelmiş hali. Parametre + gradient + optimizer state'i GPU'lara böl, ihtiyacın olduğu anda all-gather, kullan, at.
ZeRO'nun pazarlığı çok güzel: 7.5B parametre, 64-DP üzerinde standart DP 120 GB ister; ZeRO Stage 3 1.88 GB. 64× azalma. Communication overhead'i sadece 1.5× baseline DP. Bu yüzden Llama 3 paper'ı 16K H100'de 4D paralelizm kullanıyor (TP × CP × PP × DP). MFU (Model FLOPs Utilization) %38-43.
Bütün bunlar olmadan bir 405B modelin ağırlık ve optimizer state'i tek bir GPU'ya sığmaz. ZeRO-3 / FSDP modern büyük model eğitiminin nefes borusu.
> Pratik kural: 7-13B'ye kadar tek node FSDP yeter. 30-70B için TP + FSDP melez. 100B+ için TP + PP + FSDP üçü birlikte.
3. Pretraining → SFT: "Asistan" Olmak
Pretrained base model elinde var. Onu prompt'la besle, ne yapar? Karpathy'nin nanoGPT cousin'i build-nanogpt'nin README'sinde yazdığı gibi: "GPT-2 ve GPT-3 sadece internet dokümanlarını rüya görür." Yani devamına yazmaya çalışır. "Soru sor — cevap ver" formatı yok kafasında.
SFT (Supervised Fine-Tuning) base modeli asistan davranışına çekiyor. Daha az veri, daha kısa süre, ama büyük etki.
Veri formatı
<|user|>
Türkçe'de eklemeli dil ne demek?
<|assistant|>
Eklemeli (agglutinative) bir dilde kelimeler, kök bir morfeme arka arkaya
eklenen eklerle yapı kazanır. Türkçe, Fince, Macarca eklemelidir...
Bu formatlı 100K-1M örnek topla, base model üzerinde mini bir cross-entropy fine-tune koştur. Tek püf nokta: loss'u sadece response token'ları üzerinde hesapla. Prompt token'larından gradient akışına izin verme — modelin kullanıcının yazdığını "öğrenmesi" gerek yok, sadece nasıl cevap verileceğini öğrensin.
HuggingFace TRL'nin SFTTrainer'ında bu assistant_only_loss=True ile bir kelimelik bir ayar. Mart 2026'da TRL v1 yayınlandı, lansman blog'u şu başlığı seçmişti: "Post-Training Library That Holds When the Field Invalidates Its Own Assumptions." 2024'te kanun bilinen şeyler 2025'te yanlışlandı, kütüphane buna ayak uydurdu.
SFT veri kaynakları — ve neden çoğu sentetik
InstructGPT (2022) yaklaşık 40 insan etiketleyici ile SFT dataset'i yarattı. Bu emek-yoğun yaklaşım 2026'da nadir. Şimdi sıralama:
- Alpaca, Dolly, OpenAssistant — 2023 jenerasyon, ~50K-100K örnek, ağırlıklı insan.
- UltraChat, ShareGPT, OpenHermes — büyük ölçek, kullanıcı log'lardan damıtılmış.
- Magpie — base model'a kendi instruction'ını ürettir, sonra cevabını üret. Veri zincirinin başında insan emek yok.
- Self-Instruct → Evol-Instruct — GPT-4'e "bu prompt'u daha zorlaştır, daha derin sor" diye iteratif evrim ettir.
Phi-4 raporu burada da provokatif: onlarca sentetik dataset tipiyle synthetic-first yaklaşımın bayrak taşıyıcısı. Sonuç çalışıyor, ama Microsoft kendi raporunda da uyarıyor: synthetic-only modeller knowledge-heavy benchmark'larda düşüyor. Karışım şart.
LoRA ve QLoRA — fine-tune'u herkes için aç
Tam SFT için 70B modelin tam ağırlıklarını güncellemek? 280 GB ağırlık + 280 GB gradient + 560 GB Adam state = terabyte-class GPU clusters. Hobby değil.
Microsoft'un 2021 paper'ı LoRA (Low-Rank Adaptation) bu dengeyi kırdı: ana modeli dondurursun, her transformer matrisine küçük bir "rank decomposition" eklersin (W + ΔW = W + B·A şeklinde, B ve A çok daha küçük). Sadece B ve A'yı eğitiyorsun.
Paper'ın somut iddiası: Adam'la fine-tune edilen GPT-3 175B'ye kıyasla LoRA, eğitilebilir parametre sayısını 10.000 kat, GPU bellek ihtiyacını 3 kat azaltıyor — ve model kalitesinde tam fine-tune'a eşit ya da daha iyi. Tipik rank r=8 veya r=16. Adapter'lardan farkı: inference sırasında matrisleri merge edebiliyorsun, ekstra latency yok.
QLoRA (Dettmers 2023) bunu bir adım ileri taşıdı. Base modeli 4-bit'e quantize et (NF4 formatı), sonra LoRA adapter'ı 16-bit'te eğit. Üç inovasyon:
- NF4 (4-bit NormalFloat) — normal-dağılım'da optimal 16 seviye
- Double quantization — quantization sabitlerini de quantize et
- Paged optimizers — bellek spike'larını NVIDIA unified memory ile yönet
Sonuç: 65B parameter model'i tek 48GB GPU'da 24 saatte fine-tune ediyor. Guanaco modeli Vicuna benchmark'ta ChatGPT'nin %99.3 performansı.
Bu sayılar 2023'te uçuk geliyordu, 2026'da herkes pratikte kullanıyor. Hobbyist'ler için fine-tune'un eşiği bir RTX 4090. Karpathy "GPT-2 (124M) artık 1 saat ve $10'a reproduce ediliyor" diyor build-nanogpt repo'sunda. Hobbi LLM'cilik bir araştırma alanı haline geldi.
Catastrophic forgetting
SFT'nin bir bedeli var: model SFT verisindeki dağılıma "yapışırsa" pretraining'deki genel yeteneklerini kaybeder. Buna catastrophic forgetting denir. Çareler:
- Replay: SFT verisine küçük bir pretraining batch karışımı ekle.
- KL constraint: yeni modelin dağılımı base'den çok uzaklaşmasın.
- Mix carefully: instruction-following + chat + coding + math'ı dengeli karıştır.
Llama 3 paper'ı bu dengenin nasıl tutulduğunu anlatıyor — onlar SFT + DPO döngüsünü çoklu turlarla yapıyor, her turda "rejection sampling"le veriyi kalite-filtreliyor. 6 tur SFT + DPO. Her tur model genel yetenekleri biraz kaybediyor ama instruction-following kazanıyor; toplamda artıda kalmak için karışımın iyi olması şart.
4. Preference Tuning — RLHF, DPO ve Sonrası
SFT modeli güzel cevap veriyor. Ama bazen yalan söylüyor, bazen güvensiz cevap veriyor, bazen "ben bir AI modeliyim, bu konuda konuşamam" deyip kaçıyor. Bu davranışları insanın tercih ettiği yöne çekmek gerekiyor.
RLHF — InstructGPT'nin yolu
Klasik RLHF (Reinforcement Learning from Human Feedback) tarifi, InstructGPT (Ouyang 2022) paper'ında 3 aşamada:
- SFT (zaten yaptık).
- Reward Model: insanlara modelin 4-9 farklı cevabını göster, sırala. Bu sıralamalardan bir reward model eğit. InstructGPT'de RM 6B parametre seçildi, çünkü 175B RM eğitimi kararsızdı ve RL sırasında value function olarak daha az uygundu.
- PPO: Reward model skoru üzerinden policy'i (SFT modeli) PPO ile optimize et. KL penalty (π_RL ≠ π_SFT'den çok uzaklaşma) + bazen pretraining gradient karışımı (PPO-ptx variant).
Sonuçlar etkileyici. InstructGPT'nin 1.3B PPO-ptx modelinin çıktıları, 175B GPT-3'ünkilere tercih edildi — yani RLHF, 100× boyut farkına ağır basıyor. Toksisite: respectful prompt verildiğinde 175B InstructGPT, GPT-3'ten %25 daha az toksik çıktı.
Ama RLHF pahalı, kararsız ve karmaşık:
- 4 model eğitilir/saklanır: SFT, RM, policy, value function
- PPO döngüsü sample-inefficient
- KL hyperparam'ı çekip duruyorsun
- Reward hacking riski: model RM'yi kandırmayı öğreniyor

DPO — RM lazım değilmiş
2023'te Rafailov et al. provokatif bir gözlem yaptı: RLHF'in tam optimizasyon problemi, kapalı formda yazılabilir. RM eğitmen, PPO koşturman gerekmiyor. Tek bir classification loss yeterli.
Türetme matematiksel ama sezgisi şu: RLHF'in KL-constrained reward maximization probleminin optimal policy'si kapalı formdadır (Eq. 4):
π*(y|x) ∝ π_ref(y|x) · exp((1/β) r(x,y))
Bunu Bradley-Terry tercih modeline (insan A'yı B'ye tercih etti) yerleştirince partition function Z(x) sadeleşir. Geriye kalan:
L_DPO = -log σ(β · log[π_θ(y_w)/π_ref(y_w)] - β · log[π_θ(y_l)/π_ref(y_l)])
Tek hyperparameter: β. Reference policy: donmuş SFT modelin. İhtiyaç duyulan: (prompt, chosen, rejected) üçlülerinden oluşan bir tercih dataset'i.
Bir örnek nasıl görünür? UltraFeedback'ten:
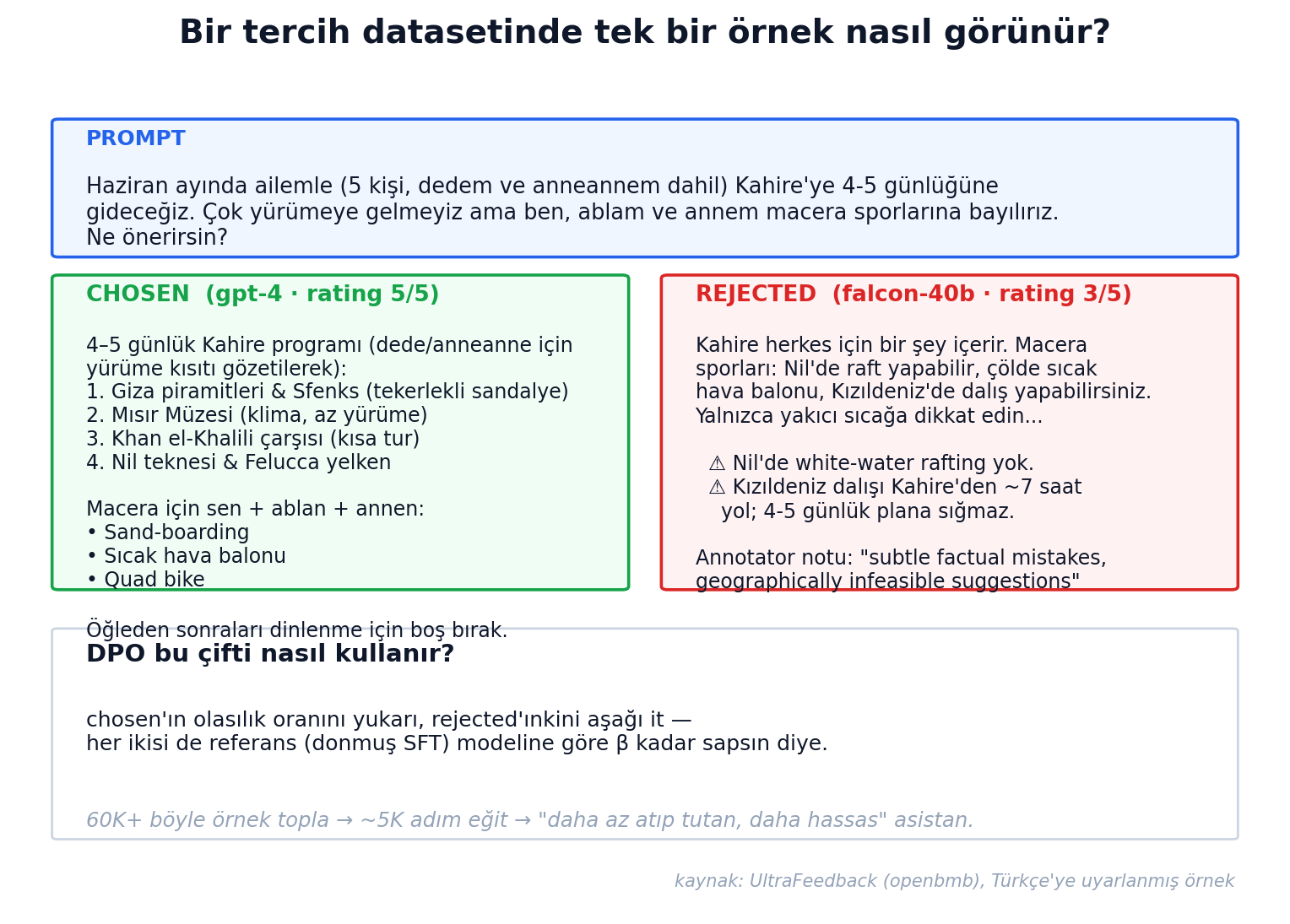
OpenBMB'nin UltraFeedback dataset'i 64K prompt × 4 cevap = 256K cevap üzerinden 380K tercih çifti. Her cevap GPT-4 ile instruction-following, truthfulness, honesty, helpfulness boyutlarında 1-5 arası annot edilmiş. RLHF/DPO literatürünün de facto referans datasetı.
DPO paper'ının ana iddiası: 6B'ye kadar modellerde — sentiment, özetleme, diyalog gibi görevlerde — tercihten öğrenmede DPO en az PPO-tabanlı RLHF kadar etkili. Üstüne: ~10× daha az compute, çok daha basit kod.
DPO bütün açık-kaynak ekosistemini silip süpürdü. Llama 3, Phi-4, Qwen, Mistral — hepsinin post-training'inde DPO veya türevi var. HuggingFace TRL'in DPOTrainer'ında bugün 12+ loss variant'ı: sigmoid (klasik DPO), hinge, ipo (KL'siz), apo, nca, bco, sppo, simpo. Hangisi en iyi? 2026 hâlâ "deneyle bul" çağında.
Önemli yan not: DPO bitti anlamına gelmez. 2024'te bir paper'ın başlığı "Is DPO Superior to PPO?" idi ve tablosunda PPO bütün deneylerde DPO'yu geçmişti. DataVLab'ın Mayıs 2026 yazısı durumu özetliyor:
> RLHF ölmedi; DPO da tam bir ikame değil. 2026'nın en iyi alignment pipeline'ları ikisini birden kullanıyor — ideolojiye göre değil, kullanım senaryosuna göre seçerek.
Frontier modeller (Claude, GPT-5 ailesi) iç pipeline'larında PPO'yu hâlâ kullanıyor — özellikle online/iterative training için. Open-weight modeller maliyet ve basitlik için ağırlıklı DPO'da. Frontier ve açık ekosistem ayrı yollardan gidiyor.
Constitutional AI — etiketçi orduyu çıkar
Anthropic'in 2022 paper'ı RLAIF (RL from AI Feedback) önerdi: insanın yerine bir başka LM tercih etiketi üretsin, bir kurallar listesi ("anayasa") ile yönlendirilsin. Pipeline:
- SL-CAI: helpful-only model harmful prompt'a cevap verir → kendi cevabını anayasaya göre kritik eder → revize eder → bu revize edilmişler üzerinde SFT.
- RL-CAI: SL-CAI iki cevap üretir, başka bir LM anayasaya bakıp seçer, bu AI-generated tercihten PM eğit, RLHF gibi PPO.
Anayasa örneklerinden ikisi (Türkçe): > "Asistanın son cevabının zararlı, etik dışı, ırkçı, cinsiyetçi, toksik, tehlikeli veya yasa dışı olduğu noktaları tek tek belirle." > "Asistanın cevabını; her türlü zararlı, etik dışı, ırkçı, cinsiyetçi, toksik, tehlikeli veya yasa dışı içeriği çıkaracak şekilde yeniden yaz."
Anthropic 16 ayrı principle yazdı ve her karşılaştırma etiketi için rastgele birini seçti — tek bir principle'da ısrar yerine bir ensemble. Claude'un karakter dengesi bu pipeline'dan geliyor.
Pratik fayda: harmful prompt'a "I can't help with that" deyip kaçmıyor — neden reddettiğini açıklayan non-evasive cevap veriyor. Bu evasiveness problemini çözüyor.
5. Reasoning RL — R1 Devrimi
2025 Ocak'ında DeepSeek-AI bir paper yayınladı: R1-Zero ve R1. Açık ağırlıklı, MIT lisanslı. Batı bir gece şok yaşadı.
R1-Zero'nun teknik özünde GRPO (Group Relative Policy Optimization) yatıyor. PPO'dan kritik fark: critic ağı yok. PPO'da policy ile aynı boyutta bir value network eğitirsin (bellek + flop iki katı). GRPO'da bunu grup ortalamasıyla değiştiriyor.
Mantık: aynı soru q için old policy'den G farklı cevap örnekle (G=64 tipik). Her birinin reward'ı r_i. Bir cevabın advantage'ı: kendi reward'ı eksi grup ortalaması, grup standart sapmasıyla normalize:
A_i = (r_i - mean(r_1..r_G)) / std(r_1..r_G)
Critic yok, value tahmini yok. Surrogate loss neredeyse PPO ile aynı (clipped), tek değişen advantage hesabı. Cameron R. Wolfe substack'inde özetliyor: GRPO'nun critic kullanmaması yalnız PPO'ya kıyasla compute'tan tasarruf etmiyor, bellek tüketimini de ciddi düşürüyor — artık iki model yerine tek model eğitiyorsun.
Verifiable rewards — RM bile lazım değil
GRPO'nun büyüsü reward sinyali. R1-Zero kural tabanlı reward kullanıyor, neural RM yok:
- Accuracy reward: Matematik cevabı
\boxed{}içinde doğru mu? LeetCode kodu test'i geçiyor mu? - Format reward: Cevap
......formatında mı?
Bu kadar. Reward hacking riski yok çünkü RM yok. DeepSeek paper'ı net: R1-Zero'da ne sonuç ne süreç temelli neural reward model kullanıyorlar, çünkü large-scale RL'de neural RM'in reward hacking'e açık olduğunu görmüşler.
Sonuç: AIME 2024 matematik benchmark'ı, pass@1 71.0%, majority voting (cons@16) 86.7%. OpenAI o1-0912'yi geçiyor. Pure RL ile, SFT olmadan.
"Aha moment"
R1-Zero eğitimi sırasında bir şey daha çıktı: model, eğitimin ortasında bir adım geri gidip yeniden düşünme davranışını kendi keşfetti. Paper Table 3'te bir intermediate koşunun ham çıktısı var:
> "Wait, wait. Wait. That's an aha moment I can flag here. Let's reevaluate this step-by-step to identify if the correct sum can be..."
Yazarlar bunu bir kutuya koymuş. Yorumları şöyle: bu an yalnız model için değil, davranışını izleyen araştırmacılar için de bir "aha moment". RL'ın gücü ve güzelliği tam burada — modele problemi nasıl çözeceğini açıkça öğretmiyorsun; doğru teşvikleri veriyorsun, gerisini kendi başına, gelişmiş çözüm stratejileri geliştirerek hallediyor.
Model "kendine reevaluate et" diye söylemeyi öğrendi. Buna chain-of-thought emergence denir ve RL'ın klasik supervised learning'le bir farkı. Karpathy bu süreçte RL'ı eleştirmiyor değil:
> "You've done all this work that could be a minute of rollout, and you're sucking the bits of supervision of the final reward signal through a straw and you're broadcasting that across the entire trajectory and using that to upweight or downweight that trajectory. It's just stupid and crazy."
> "Reinforcement learning is terrible. It just so happens that everything that we had before it is much worse."
"Sucking supervision through a straw" — bu cümle artık RL'ın canonical critiği. Doğru bile. Ama açık bir alternatif yok.
Sınırlar — RLVR'ın çalışmadığı yerler
GRPO + verifiable rewards (RLVR) reasoning'de patladı çünkü reward sinyali kesin: matematik cevabı, kod test'i, mantık puzzle'ı. Cameron R. Wolfe'un Şubat 2026 yazısı:
> RLVR'a çok emek harcandı; ama LLM'lerin yüksek-değerli birçok kullanımı — uzun-form soru-cevap, genel yardımseverlik — doğruluğun binary bir sinyalle yeterince yakalanamadığı, doğası gereği öznel alanlarda çalışıyor.
Yani "iyi şiir yaz" için binary reward yok. Bunun için rubric-based rewards çalışması başladı: prompt-specific checklist, LLM judge ile sub-goal değerlendirmesi. Constitutional AI'ın akrabası, daha mühendislik-yoğun.
2026'da o1, R1, Gemini Deep Think, Claude extended thinking, GPT-5 Thinking — hepsinin altında benzer formül var. Detaylar kapalı kaynak; açık paper'larda DeepSeek lider.
6. Ne Kadar Tutuyor? — $6 Milyon Efsanesi
DeepSeek-V3 (Aralık 2024) paper'ı "2.788M H800 GPU saat" diyor. Saat başına ~$2 USD varsayımıyla ~$5.6M çıkıyor. Bu sayı tüm sektörde dolaştı: "DeepSeek $6M'a frontier model eğitti, $100M+ OpenAI maliyetleri ne?"
Bu yanlış anlatım. SemiAnalysis (Dylan Patel) 30 Ocak 2025'te düzeltti:
> Paper'daki $6M rakamı yalnız pre-training koşusunun GPU maliyeti — modelin toplam maliyetinin küçük bir parçası. Bir ürünün malzeme listesindeki tek bir kalemi gösterip "işte tüm maliyet bu" demeye benziyor.
DeepSeek'in toplam donanım yatırımı $500M+. 50,000 Hopper GPU envanteri. Pre-training run sadece final koşu — R&D, ablation, sentetik veri üretimi, post-training dahil değil. "Çayhane operasyonu" değil.
Ama asıl ders şu: algoritmik ilerleme + donanım sayesinde maliyet eğrisi düşüyor. 2019'da GPT-2 (124M) eğitmek günler sürerdi; 2026'da Karpathy "~1 saat, ~$10" diyor. Bu eğri model boyutuyla beraber kayıyor. 7B sınıfı model bugün ~$50K civarında pretraining (henüz expert-level değil ama olabilir-tarzı bir yerde).
Nathan Lambert'in Nisan 2026 "My bets on open models" yazısı bunun yapısal sonucunu söylüyor:
> Frontier'a yakın (ama tam frontier olmayan) güçlü modelleri eğitmek, büyük-ölçek deployment'lara kıyasla görece küçük bir maliyet. Örn. ABD belli bir compute eşiğinin üstündeki açık modelleri yasaklasa bile, başka bir egemen aktör eninde sonunda onları eğitip kamuya açar.
Eğitim yasaklanamayacak kadar ucuzladı. Birinin yapması yeterli, dünya görür.
7. Yaygın Yanlış Anlamalar
Gövdede dağılmış birkaç efsaneyi zaten geçtik: Chinchilla'nın "daha çok parametre = daha iyi" yıkımı, RLHF'in zeka katmadığı (yalnız asistan kişiliğini biçimlendirdiği), GRPO'nun PPO'yu tümden ikame etmediği ve $6M meselesi. Geriye gövdede durmayan iki nokta kalıyor:
> - "Halüsinasyon RLHF / preference tuning ile yamalanır." OpenAI'ın Eylül 2025 paper'ı ("Why Language Models Hallucinate") tersini söylüyor: modeller halüsinasyon görüyor çünkü eğitim ve değerlendirme prosedürleri, belirsizliği kabul etmek yerine tahmin etmeyi ödüllendiriyor. Mimari değil, teşvik mimarisi problemi. > - "Open weight = açık eğitim." Genelde değil — ağırlık açık ama veri ve kod kapalı; tam reproducible eğitim hâlâ nadir. İstisna var: AI2'nin OLMo / OLMo 2 ve Tülu serisi veriyi, kodu ve checkpoint'leri birlikte açıyor — uçtan uca yeniden üretilebilir eğitimin kanonik örnekleri.
8. Sırada Ne? — Üç Farklı Profile Yol Haritası
1. "Anlamak istiyorum" — Karpathy'nin Let's reproduce GPT-2 videosu (4 saat, YouTube) hâlâ altın standart. Sebastian Raschka'nın Manning kitabı Build a Large Language Model (From Scratch) (2024) en derli toplu yazılı kaynak. nanoGPT repo'sundaki train_shakespeare_char.py'i CPU'da çalıştır — laptop'unda 3 dakikada minik bir transformer eğit.
2. "Kendim deneyeceğim" — Karpathy'nin nanochat (nanoGPT'nin yeni nesli) repo'su artık standart. Hobbyist için: küçük Türkçe pretrain (~100M-1B), HuggingFace TRL ile LoRA SFT + DPO. Eğitim için bir RTX 4090 yeterli, daha büyüğü için RunPod / Lambda saatlik kiralık.
3. "İleri seviye" — HuggingFace TRL kütüphanesi (SFTTrainer, DPOTrainer, GRPOTrainer, hepsi v1.4 API), PyTorch FSDP tutorial'ları, DeepSpeed ZeRO-3 config'leri, vLLM ile inference serving. DeepSeek-V3 ve Llama 3 paper'ları okumayı bekliyor — birer hafta sonu projesi.
Kapanış
Açılıştaki o tek cümleye geri dönelim — ama bu sefer her kelime ağırlığını taşıyor:
- 15.6T tokens — FineWeb stili bir pipeline'ın binlerce mühendis-saati. MinHash, fastText, KenLM.
- FSDP on 16K H100 — ZeRO-3'ün PyTorch native uygulaması, 4D paralelizm, MFU %38-43. 54 günde 419 beklenmedik interrupt'a (çoğu donanım) rağmen ayakta tutulmuş bir cluster.
- SFT on UltraChat — büyük çoğunluğu sentetik bir veriyle base modelin asistana dönmesi. Loss yalnız response token'larında.
- DPO on UltraFeedback — bir reward model + PPO döngüsünün tek classification loss'una indirgenmiş hâli. Eq. 7, β, donmuş reference policy.
- GRPO with verifiable rewards — critic ağı olmayan, grup-relatif advantage'lı, matematik ve kod test'leriyle ödüllendirilen pure-RL. R1-Zero'nun "aha anı" buradan çıkıyor.
Tek cümle, beş ayrı dünya. Her birinin altında bir paper, her paper'ın altında 50-100 mühendisin bir yıllık emeği var. Bütün bir yığın, model kartının ilk satırında bir nefese sığmış sana sunuluyor.
Üç yazılık dizi tamam. Birinci yazıda kavramları çevirdik, ikincide mimariyi söktük, üçüncüde inşaatı gezdik. Karpathy'nin dediği gibi, yoktan bilgi yaratılmıyor: eğitim sürecindeki her şey — verinin nereden geldiği, hangi optimizer'la nasıl harmanlandığı, hangi geri bildirimle eğildiği — modele giren bilgidir.
Ödevin var: bir açık model kartı (Llama 3.1 405B, DeepSeek-V3 ya da Qwen 3) seç. Paper'ını aç. Bu yazıdaki dört evrenin her birini kâğıda yaz: bu model şu adımı kim, ne kadar veriyle, hangi loss'la yaptı? Boş kalan yer var mı? Niye? "Open weight" ne kadar "open"?
Sonra git, kendi nanoGPT'ni eğit. Loss spike gör. Warmup'ı düzelt. Bir paragraf yaz. Bir sonraki sefer başkasının model kartını değil, kendi notlarını oku.
Bu yazıyı yazarken bir agent takımı kullandım: bir Firecrawl avcısı 20+ paper ve sektör yazısını tarayıp _research_notes.md dosyasına yatırdı, bir Python ressamı sekiz görseli üretti, bir nanoGPT eğitimi bir gerçek loss eğrisi sağladı, ve bir ses denetçisi önceki iki yazıyı yan masada açık tutup tonu kalibre etti. Hâlâ insan elinden çıkmış bir yazı — ama hâlâ "bir kişi" tarafından yazılmış da değil. 2026'da yazı işi bu.
Bu üçleme şimdilik tamam. Bir sonraki yazıda satır satır kendi mini-LLM'imizi inşa edelim — pretraining'den DPO'ya, kod ve yorumlarla.
Kaynakça
Birincil paper'lar
- Ouyang et al. 2022, Training language models to follow instructions with human feedback (InstructGPT) — arxiv.org/abs/2203.02155
- Rafailov et al. 2023, Direct Preference Optimization — arxiv.org/abs/2305.18290
- DeepSeek-AI 2025, DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning — arxiv.org/abs/2501.12948
- DeepSeek-AI 2024, DeepSeek-V3 Technical Report — arxiv.org/abs/2412.19437
- Bai et al. 2022 (Anthropic), Constitutional AI: Harmlessness from AI Feedback — arxiv.org/abs/2212.08073
- Grattafiori et al. 2024 (Meta), The Llama 3 Herd of Models — arxiv.org/abs/2407.21783
- Hoffmann et al. 2022 (DeepMind), Training Compute-Optimal Large Language Models (Chinchilla) — arxiv.org/abs/2203.15556
- Penedo et al. 2024 (HuggingFace), The FineWeb Datasets — arxiv.org/abs/2406.17557
- Abdin et al. 2024 (Microsoft), Phi-4 Technical Report — arxiv.org/abs/2412.08905
- Kalai, Nachum, Vempala, Zhang 2025 (OpenAI), Why Language Models Hallucinate — arxiv.org/abs/2509.04664
- Rajbhandari et al. 2020 (Microsoft DeepSpeed), ZeRO: Memory Optimizations Toward Training Trillion Parameter Models — arxiv.org/abs/1910.02054
- Hu et al. 2021 (Microsoft), LoRA: Low-Rank Adaptation of Large Language Models — arxiv.org/abs/2106.09685
- Dettmers et al. 2023, QLoRA: Efficient Finetuning of Quantized LLMs — arxiv.org/abs/2305.14314
- Hu et al. 2024, MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies (WSD) — arxiv.org/abs/2404.06395
- Shumailov et al. 2023 / Nature 2024, The Curse of Recursion: Training on Generated Data Makes Models Forget — arxiv.org/abs/2305.17493
Sektör analizleri (2025-2026)
- Nathan Lambert (Interconnects), My bets on open models, mid-2026 — Nisan 2026
- Cameron R. Wolfe (Deep Learning Focus), Group Relative Policy Optimization
- SemiAnalysis (Dylan Patel), DeepSeek Debates: Chinese Leadership On Cost, True Training Cost — Ocak 2025
- Communications of the ACM, Model Collapse Is Already Happening, We Just Pretend It Isn't — Mart 2026
- Andrej Karpathy, Dwarkesh Podcast 2025 (RL & model collapse yorumları)
Pratik araçlar
- HuggingFace TRL v1 — github.com/huggingface/trl
- Karpathy nanoGPT / nanochat — github.com/karpathy/nanoGPT / karpathy/nanochat
- Karpathy Let's reproduce GPT-2 (124M) — youtube.com/watch?v=l8pRSuU81PU
- Sebastian Raschka, Build a Large Language Model (From Scratch) — Manning 2024
- UltraFeedback dataset — huggingface.co/datasets/openbmb/UltraFeedback
- NVIDIA Transformer Engine (FP8) — docs.nvidia.com/deeplearning/transformer-engine
Finis