Bir LLM cevap üretirken, dünyanın en pahalı silikonu çoğunlukla bekliyor. Hesap yapmıyor. Bekliyor. H100 saniyede 989 trilyon FP16 işlemi yapabiliyor; aynı H100, sıradan bir decode adımında yeteneğinin yüzde birini bile kullanmıyor. İlk okuduğumda cümleye iki defa geri döndüm — 30 bin dolarlık bir çip, en yaygın işinde silikonunun büyük çoğunluğunu boşa harcıyor.
Sebebi tek satıra sığıyor: decode memory-bound. Modelin 141 GB'lık ağırlığını HBM'den tensor core'una taşımak — H100'ün 3.35 TB/s bant genişliğinde — yaklaşık 42 milisaniye. Çekildikten sonraki gerçek hesap mikro-saniyeler. Aradaki tüm zaman ulaşım. Modern LLM inference mühendisliğinin neredeyse her satırı, bu 42 milisaniyenin içine başka iş sıkıştırmak için yazılıyor: KV cache yönetimi, PagedAttention, continuous batching, speculative decoding, FP8 kernel'leri, quantization. Hepsi aynı bekleme süresine konmuş farklı adlar.
Çoğu mühendis için eğitim "fancy"dir — paper okur, GPU kümesinden bahseder, "ben de bunu yapabilirim" der. Inference ise "infra işi" diye anılıp geçilir. Yanlış. 2026'da, frontier LLM şirketlerinin harcamalarının büyük çoğunluğu inference'a gidiyor. Eğitim bir kez yapılır, inference her gün milyarlarca kez. Ekonominin asıl tarafı artık burada.
Önceki üç yazıda kavramları (token, embedding, parametre), mimariyi (attention, RoPE, GQA) ve eğitimi (pretraining → SFT → DPO → GRPO) sökmüştük. Bu yazı dörtleyi tamamlıyor: modeli çalıştırmak. Eğitilmiş bir LLM cevap üretirken altında neler dönüyor? Aynı parametre sayısı, aynı GPU — neden bir framework saniyede 12 token üretirken diğeri 240 üretebiliyor? DeepSeek-V3 671 milyar parametreyi nasıl $0.43 / 1M token'a serve edebiliyor? Cerebras Llama 70B'yi nasıl saniyede 2,100 token üretebiliyor — sıradan bir H100'ün on katı?
Sekiz mühendislik katmanı var altında. Sırayla.
Sekiz katmanın tek paragraflık özetleri:
Prefill vs Decode: Inference'ın iki ayrı fazı, çok farklı darboğazlarla. Bunu anlamak işin %80'i.
KV Cache: Modelin kısa-vadeli hafızası. GPU belleğini en çok yiyen şey. PagedAttention bu krizi işletim sisteminden ödünç aldığı bir hileyle çözdü.
Continuous Batching: 2022'de Orca'nın getirdiği fikir — eski statik batching GPU'yu yarı boş gezdiriyordu. vLLM, TGI, TRT-LLM, SGLang — hepsi bu fikrin üstüne kurulu.
Decoding stratejileri: greedy / top-k / top-p / min-p / mirostat. Modelin "bir sonraki token"ı seçme sanatı. Aynı model, farklı sampler ile bambaşka çıktılar verir.
Speculative decoding: Küçük bir model büyük modele "şunlar geliyor olabilir mi?" diye sorar; doğruyu yakaladığında bedavaya 4-5 token kazandırır. 2-3× hız, çıktı dağılımı değişmeden.
Quantization: Ağırlıkları 16-bit'ten 4-bit'e indirip belleği ve bant genişliğini yarıdan da aşağı çekmek. GPTQ, AWQ, GGUF, FP8, NVFP4. Frontier'a giden köprü.
Donanım: H100 → H200 → Blackwell B200 → MI325X → Cerebras WSE-3 → Apple M3 Ultra. Her birinin farklı bir matematiği var.
Pricing: 2026 Mayıs itibariyle $/M token rekabeti. Frontier modelinin token başına maliyeti son bir yılda %80'e yakın düştü.
Birinci katmandan başlayalım — prefill ile decode arasındaki gerçek fark.
1. Prefill vs Decode — İki Ayrı Dünya
LLM bir cevap üretirken iki bambaşka şey yapıyor. Bu ikisini ayırt etmeden, inference'la ilgili hiçbir tartışma anlam kazanmıyor.
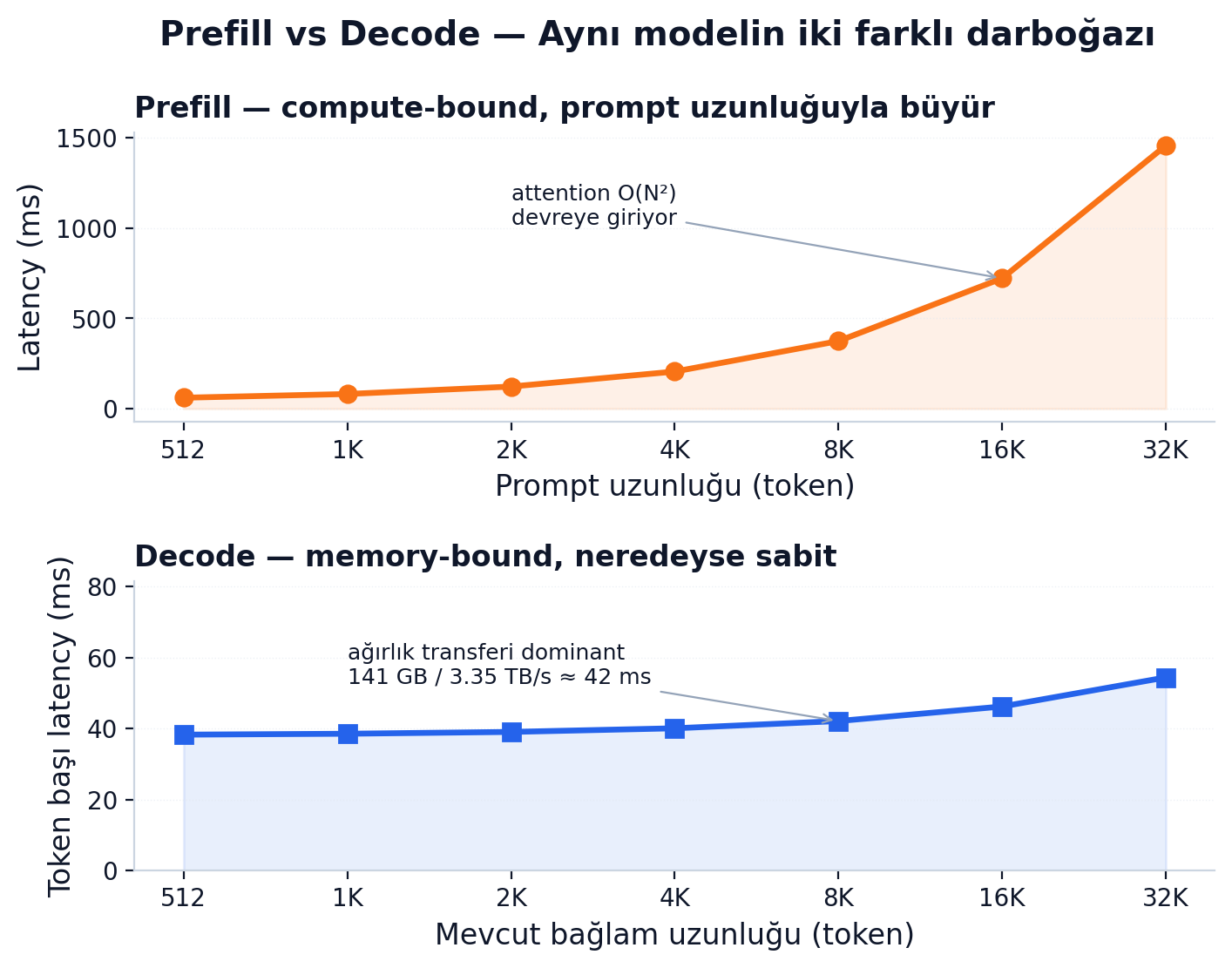
Prefill (önyükleme): Kullanıcının prompt'unu modele veriyorsun. Diyelim 2,000 token'lık bir cümle yazdın. Model bu 2,000 token'ın hepsini aynı anda transformer'dan geçirir. Tek bir paralel forward pass. Çıktısı: her token için bir attention ve activation tablosu, ve son token'dan ilk yeni token. Bu fazın darboğazı hesap (compute) — büyük bir matris çarpımı, GPU'nun tensor core'larını doyuruyor. Yeterince paralel, yeterince doyurucu bir işyükü.
Decode (üretim): Şimdi modelin yeni token'ları otoregresif olarak üretmesi gerekiyor. Her yeni token için, modelin tüm ağırlıklarını GPU belleğinden okuması lazım. Llama 70B BF16'da 141 GB. Her token için 141 GB. H100'ün 3.35 TB/s bant genişliğinde, ham olarak 42 ms civarı — yani teorik olarak saniyede ~24 token. Bu fazın darboğazı bellek bant genişliği, hesap değil.
Databricks'in inference best-practices yazısı bunu tek cümleye indiriyor: decode sırasında matris çarpımlarının bir boyutu küçük kaldığı için hız, modeli ne kadar hızlı hesapladığına değil, ağırlıkları GPU belleğinden ne kadar hızlı okuyabildiğine bağlı. Yazının kendi formülasyonuyla:
> "Available and achieved memory bandwidth … is a better predictor of speed of token generation than their peak compute performance."
Bu tek cümle, modern inference mühendisliğinin neredeyse her tasarım kararını açıklıyor.
İki türetilmiş metrik var, ikisi de pratikte her benchmark'ta görüyorsun:
TTFT (Time to First Token) — prompt'u yolladıktan sonra modelin ilk cevap token'ını üretene kadar geçen süre. Prefill maliyeti + bir decode adımı. Sohbet uygulamaları için kritik — kullanıcının "model donmuş mu?" diye düşünmediği eşik bu.
TPOT (Time per Output Token) — sonraki her bir token için geçen süre. Decode hızı. Tipik tek-istek bağlamında 30-100 ms arası. Kullanıcının okumayı sürdürebildiği akışa karşılık geliyor.
Toplam gecikme şu sade formülde toplanır:
Latency = TTFT + N × TPOT
Çıktı uzunluğu N büyüdükçe TPOT baskın oluyor. 500 token cevap, 50 ms TPOT → 25 saniye sadece üretim. TTFT'nin 500 ms'lik bir gecikmesi gürültü kalıyor. Önemli sezgi: uzun cevaplarda darboğaz decode'da, kısa cevaplarda prefill'de.
Prefill ve decode'un farklı darboğazları olması, modern serving framework'lerinin "disaggregated serving" diye anılan bir mimari hareketini de açıklıyor. Prefill'i bir GPU grubu, decode'u başka bir grup yapsın. NVIDIA TensorRT-LLM'in 2025 sonlarında ortaya çıkardığı dezagrege mimari tam bu fikri uyguluyor. Llama 4 Maverick gibi MoE modellerde ayrımı daha kıyasıya hissediyorsun — prefill expert dağılımı yoğun, decode tek-istek expert routing'i seyrek.
Aynı prefill ve decode gerilimini ters yönden çözen ikinci bir koz da var: chunked prefill. Uzun bir prompt'u tek hamlede işlemek yerine küçük parçalara (chunk) bölüp her parçayı decode adımlarıyla aynı batch'te koşturuyorsun. Böylece dev bir prefill, arkadaki decode'ları uzun uzun bekletmiyor — uzun prompt'lar akarken bile TPOT (token-arası gecikme) stabil kalıyor. vLLM ve SGLang'in TTFT ile TPOT dengesini ayarlamak için kullandığı asıl kaldıraç bu: disaggregation "fazları ayrı GPU'lara böl" derken, chunked prefill "fazları aynı GPU'da akıllıca harmanla" diyor. İki farklı felsefe, aynı gerilim.
Bu birinci katmanı kaçırırsan, geri kalan her şey havada kalır. "Modelimi daha hızlı çalıştırmak istiyorum" sorusunun cevabı, hangi fazı hızlandırmak istediğine göre farklı.
2. KV Cache — Modelin Kısa-Vadeli Hafızası
Decode'un neden bu kadar bant genişliği-yoğun olduğunun cevabını anlamak için bir adım derine inmek lazım. Cevap: KV cache.
Attention'da her token için üç vektör hesaplanır: Query, Key, Value. Önceki yazıda bunları söktük. Decode sırasında, yeni bir token üretmek için modelin tüm önceki token'ların K ve V vektörlerine bakması gerekiyor — yoksa context'i unutur. İki seçeneğin var:
- Her yeni token'da, tüm prompt + üretilen token'lar için K ve V'yi yeniden hesapla. Saçma — N. token üretirken N-1 kez hesaplanmış şeyi tekrar hesaplamak.
- Bir kez hesapla, sakla, sonraki adımda kullan. Bu KV cache.
Saklama bedeli ne kadar? Formül:
KV_cache_bytes = 2 × L × B × S × H_kv × d_head × dtype_bytes
Llama 3 70B (L=80 katman, H_kv=8 GQA başı, d_head=128) için 8K token bağlamda, batch=1, BF16:
2 × 80 × 1 × 8192 × 8 × 128 × 2 = 2.68 GB. Tek istek için 2.68 GB sadece KV cache. 16 paralel istek isterse: 42.9 GB. H100'ün 80 GB'ından modelin 141 GB BF16 ağırlığını saymaya başlayınca, bütçenin nereye gittiği anlaşılıyor.
vLLM'in lansman blog'u problemi tek cümlede çerçeveliyor: mevcut serving sistemleri parçalanma ve aşırı-rezervasyon yüzünden GPU belleğinin %60-80'ini çöpe atıyor.
Sebep şu: klasik serving framework'leri her istek için maksimum olası context'e yetecek bir blok ayırıyor. Aslında 200 token çıktığı istek için belki 4K, belki 32K token'lık bir alan ayrılmış oluyor. Üstüne her isteğin contiguous (bitişik) bellek alması gerek — küçük "iç" delikler oluşuyor. Sonuç: GPU belleğin yarısından çoğu hava.
Berkeley'den Kwon ve arkadaşları 2023'te bunu, SOSP'taki PagedAttention paper'ında, işletim sistemlerinin klasik sanal bellek ve sayfalama (paging) tekniğinden ödünç aldığı bir analojiyle çözdü.
Analoji birebir: KV cache bloklarına bölünüyor (varsayılan 16 token), her isteğin mantıksal blokları bir block table aracılığıyla fiziksel bloklara eşleniyor. Bloklar bitişik olmak zorunda değil. Yeni token üretildikçe bloklar dinamik olarak ayrılıyor.
> "Blocks as pages, tokens as bytes, sequences as processes."
Kayıp sadece her isteğin son bloğunun yarı dolu olmasından kaynaklanıyor — paper'ın ölçtüğü: %4 altında. 60-80'den 4'e bir düşüş.
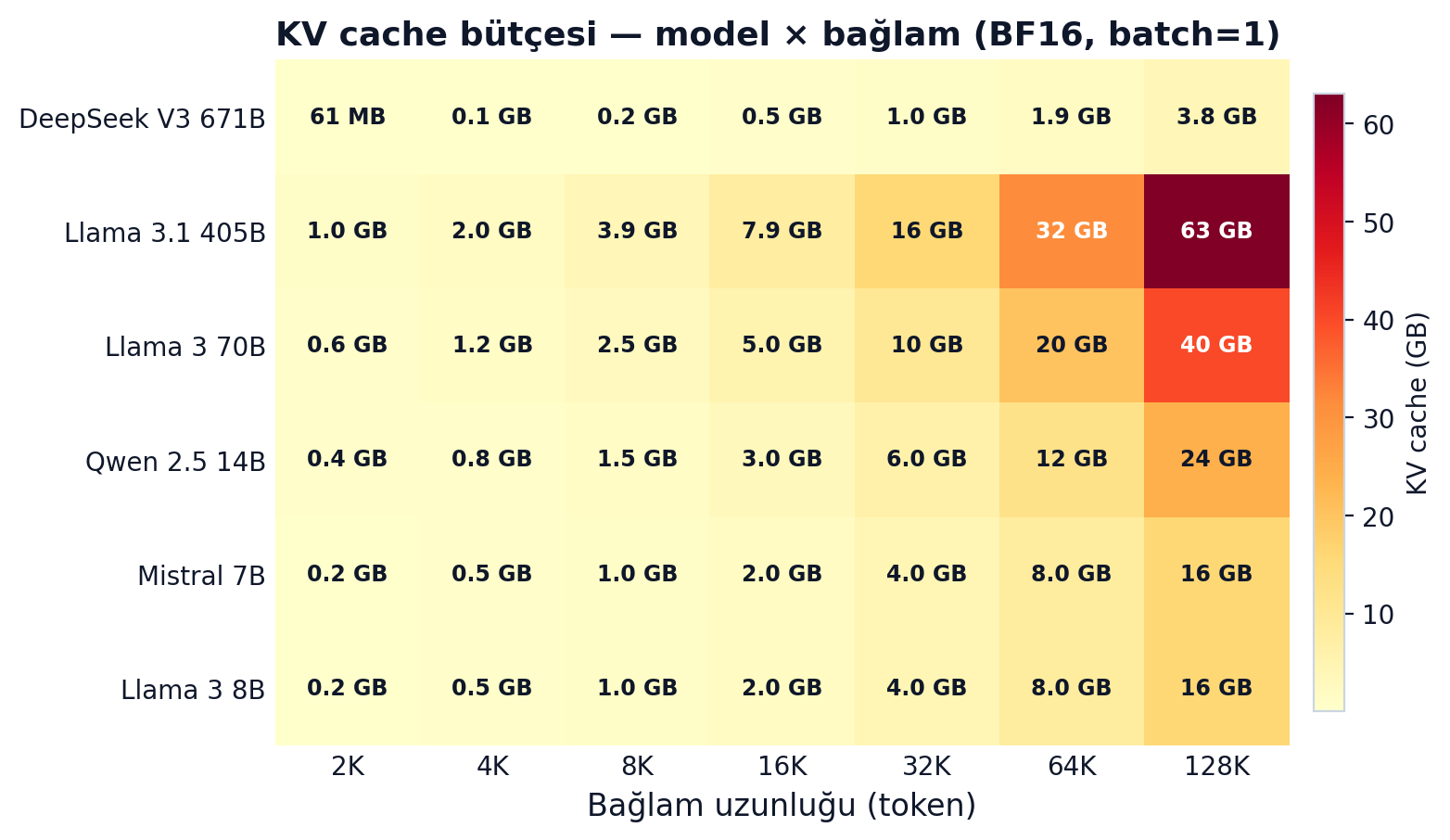
Yukarıdaki heatmap modelin boyutuyla bağlamın uzunluğunun KV cache bütçesine etkisini gösteriyor. Dikkat: 70B Llama'da 32K bağlamla bir batch=1 istek bile 10 GB civarı yiyor. 128K context, 64 paralel istek? H100 tek başına yetmiyor.
PagedAttention bu krizi çözüp 2-4× throughput kazandı, paper'ın ana iddiası. vLLM'in lansman benchmark'ı daha da iddialı: A10G + Llama 7B üzerinde HuggingFace Transformers'a karşı 14-24× throughput. PagedAttention'ın "Copy-on-Write" özelliği parallel sampling ve beam search'te belleği %55 daha aza indiriyor — paylaşımı block table üzerinden referans sayımıyla yapıyor, tıpkı fork() sonrası COW gibi.
vLLM bugün açık-kaynak LLM serving'in fiili standardı. 2024 Eylül'ünde v0.6 release'i CPU darboğazlarını törpüledi (Llama 3 8B'de 2.7× throughput, 5× daha iyi TPOT). 2025 Ocak'ında V1 engine rewrite'ı çıktı: prefix caching varsayılan, chunked prefill, hash-based KV reuse. Ocak 2026 itibariyle vLLM bütün major açık modelleri ilk gün destekliyor.
PagedAttention bir paper'ın çözebileceği en zarif problem türlerinden — bir analojinin gücüyle bir endüstri kazanılmış oluyor.
Bir tamamlayıcı not: PagedAttention KV cache'i bellekte nasıl yerleştireceğini çözüyor; hesap tarafında ona dik eksende duran teknik FlashAttention (Dao et al. 2022). FlashAttention attention'ı tiling'le bloklara bölüp devasa ara softmax matrisini HBM'e hiç yazmadan SRAM'de tutuyor — attention'ın bellek trafiğini, dolayısıyla uzun bağlamdaki maliyetini kökten azaltıyor. İkisi dik eksenlerde tamamlayıcı: biri KV cache'in bellekteki yerini, diğeri attention'ın HBM trafiğini optimize ediyor; modern serving ikisini birden koşuyor.
3. Continuous Batching — Request Takvimini Değiştirmek
KV cache problemini çözdün, hâlâ GPU yarı boş geziyor. Sebep batching.
Statik batching: 32 istek topla, hepsini birlikte forward pass'ten geçir. Sorun: istekler farklı uzunluklarda. En kısa istek 50 token'da bitti, en uzun 800 token üretiyor. Diğer 31 istek 750 step boyunca beklemek zorunda — bitmiş olan bile, batch toptan bitsin diye. GPU çoğu zaman boş.
Seoul National University ve FriendliAI'dan Yu ve arkadaşları OSDI 2022'de iteration-level scheduling önerdi — Orca paper'ı. Fikir basit: her token adımında batch'i yeniden kur. Bitmiş istekler çıksın, sıradaki gelsin. Bir step çalışırken batch dinamik.
Bu fikrin pratik etkisi paper'da büyük: GPT-3 175B servis ederken FasterTransformer'a göre aynı gecikmede 36.9× throughput. NVIDIA, HuggingFace, vLLM hepsi bu fikri farklı isimlerle adopte etti: in-flight batching, dynamic batching, continuous batching. Aynı şey.
Tek bir dürüstlük notu: continuous batching interaktif, değişken-uzunluklu trafikte neredeyse her zaman kazanıyor — ama her zaman değil. Offline, throughput'u maksimize eden toplu işlerde (tüm istekler hazır, tek tek gecikme umurunda değil) büyük bir statik batch hâlâ mantıklı olabiliyor; iteration-level scheduling'in ek defter-tutma maliyeti orada kendini geri ödemeyebilir.
vLLM 2023'te continuous batching + PagedAttention'ı birleştirip launch oldu. 2024'te SGLang (LMSYS), aynı omurganın üstüne RadixAttention ekledi: aynı prompt prefix'ini paylaşan istekler arasında KV cache'i radix tree'de paylaş. Few-shot prompting, sistem prompt'lu sohbet, ajan workflow'ları — hepsi prefix paylaşımıyla devasa kazanım. SGLang'ın v0.4 blog'u 8× A100 üzerinde, sistem prompt yüklü senaryoda cache hit'i %20'den %75'e çıkarınca 1.9× throughput kazandığını söylüyor.
NVIDIA'nın TensorRT-LLM'i kendi terimini koymuş: in-flight batching (IFB). Hopper'da FP8 kernel'leri, Blackwell'de FP4. MLPerf v5.0 Inference'ta GB200 NVL72, Llama 3.1 405B server kategorisinde H200 NVL8'in 3.4× per-GPU performansını verdi. Sistem seviyesinde 30×.
HuggingFace'in TGI'i 2024 sonunda v3'e atladı — uzun bağlamda iddialı. 8× H100 üzerinde Llama 3.1 70B, 200K token'lık prompt'ta vLLM'e karşı 13× kazanım rapor ediliyor. L4 24GB'de TGI Llama 3.1 8B'ye 30K token sığdırırken vLLM 10K'da takılıyor. Sebep: TGI v3'ün uzun prompt'ları aggressive olarak prefix cache'leyen yeni scheduler'ı.
Bir de llama.cpp var, bu zaten ayrı bir kategori: CPU-first, Apple Silicon Metal backend, CUDA backend opsiyonel. Python yok, hiçbir dependency'si yok, tek binary. GGUF formatı bütün ekosistemde 2023 Ağustos'tan beri standart. Mac Studio M3 Ultra 512GB'da, DeepSeek R1 671B Q4_K_M, Reddit r/LocalLLaMA topluluğundan: saniyede 18 token. Mac Studio tek başına 671 milyar parametreli MoE modeli ev şartında koşturuyor.
Mevzu hangi framework değil. Mevzu continuous batching + KV cache yönetimi + prefix paylaşımı üçlüsünün her ciddi serving altyapısında olduğu. Aralarındaki farklar kenar durumlarda:
- vLLM — geniş model desteği, OpenAI-uyumlu API, prefix caching varsayılan, sağlam community.
- SGLang — RadixAttention öncülü, structured output entegre (XGrammar), DeepSeek MLA için DP attention optimizasyonları.
- TensorRT-LLM — NVIDIA'nın en hızlı kernel'leri, FP4 native, MoE / dezagrege serving daha olgun.
- TGI — sıfır-config çekiyor, uzun-prompt avantajı, HuggingFace ekosistemine sıkı bağlı.
- llama.cpp — Python yok, CPU/Apple Silicon, consumer GPU, GGUF.
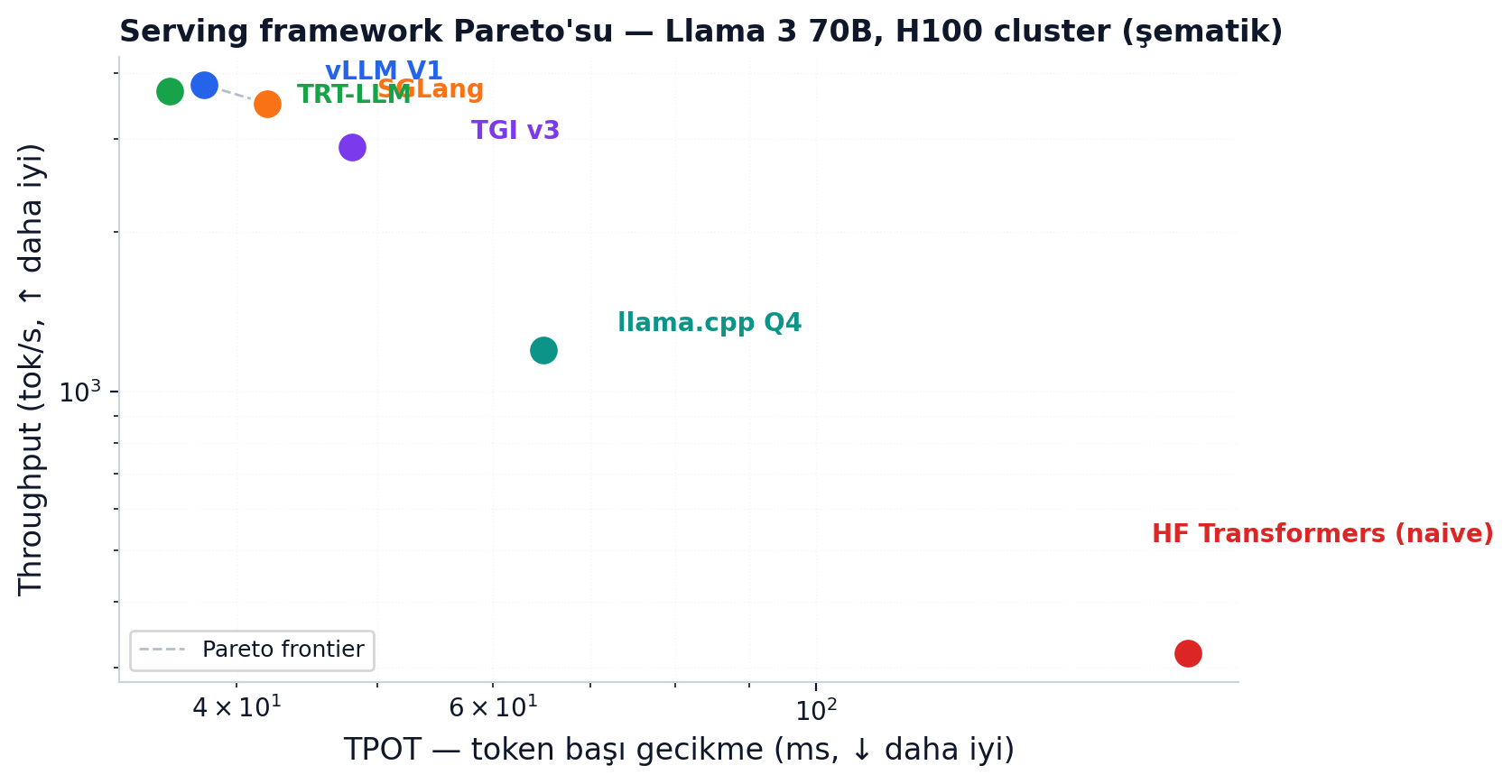
Pareto frontier'ın üzerinde olmak demek, hiçbir başka framework hem daha hızlı hem daha yüksek throughput vermiyor demek. 2026 itibariyle dört serving sistemi (vLLM V1, SGLang, TRT-LLM, TGI v3) bu frontier'ı paylaşıyor — birinin tek üstün olduğu bir dünya yok.
4. Decoding — Bir Sonraki Token'ı Seçme Sanatı
Şu ana kadar her şey iş yükünü düzene koymakla ilgiliydi. Asıl token'ı seçme kısmına gelmedik. LLM her decode adımında bir olasılık dağılımı veriyor — vocab boyutunda bir vektör, mesela 128K girdi. Sıradaki token'ı bu dağılımdan nasıl seçeceksin?
Greedy: Her zaman en yüksek olasılıklı token'ı seç. Deterministik. Boring ama matematik/kod gibi yaratıcılık aranmayan görevlerde altın standart.
Beam search: K paralel beam tut, sonunda en yüksek skorlu sekansı seç. Çeviri için yıllarca kuraldı. Açık-uçlu üretimde ise bir felaket olduğu çıktı. Holtzman ve arkadaşlarının 2019 The Curious Case of Neural Text Degeneration paper'ının saptaması net: olabilirlik (likelihood) maksimizasyonu metni tekrara ve klişeye sürüklüyor; budama yapmayan saf sampling ise modelin düşük-güvenli kuyruğundan örnekleyip komik hatalar üretiyor. İkisi de istenmiyor.
Çözüm: kuyruktan kestir. Top-k (Fan 2018) en yüksek k token'ı tut, geri kalanını at, kalanı softmax'la, ondan sample yap. Top-p / nucleus (Holtzman 2019) sabit k yerine "kümülatif olasılık 0.9'a ulaşana kadar token al" diyor — dağılım sivri olunca az token, düz olunca çok. Min-p (Nguyen 2024) ise en yüksek token'ın olasılığına oranlı bir eşik koyuyor: threshold = min_p × max(P). Sivri dağılımlarda dar, düz dağılımlarda geniş. Yüksek sıcaklıkta hâlâ kaliteli kalıyor.
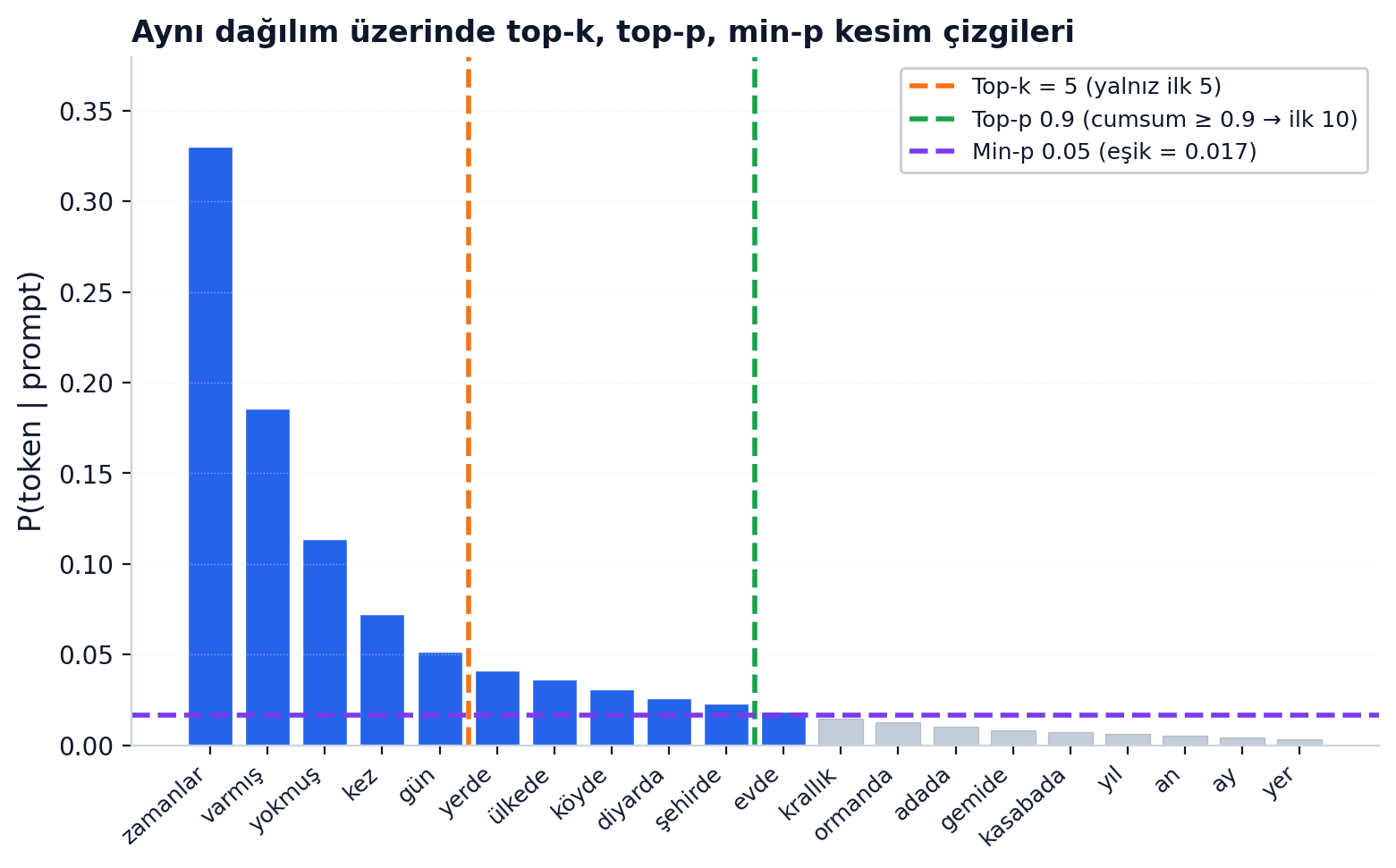
Yukarıdaki grafikte aynı dağılım üzerinde üç farklı sampler'ın hangi token'ları içeride bıraktığını görüyorsun. Top-p ve min-p en sık tartışılan ikili. 2024-2025'te birçok local-LLM topluluk modeli min-p'yi varsayılan yaptı.
Daha egzotik sampler'lar da var — typical sampling (Meister 2022; bilgi içeriğini modelin "tipik" entropisine yaklaştırır), mirostat (Basu 2020; feedback control'le hedef bir perplexity'i sabitler, uzun üretimde repetition'ı kırar) ve topluluğun DRY'ı (n-gram tekrarlarını dinamik cezalandırır) en bilinenleri — ama pratikte üretimin büyük çoğunluğu hâlâ top-p/min-p ile dönüyor.
OpenAI API'sinin frequency penalty ve presence penalty parametreleri (-2.0 ile 2.0) ek control. logit_bias ile tek tek token'ları zorlayabiliyor veya yasaklayabiliyorsun (-100 ile 100). Yapısal çıktı için ise structured output araçları: Outlines (regex/CFG), llama.cpp'nin GBNF gramerleri, ve 2024'te yayınlanan XGrammar (Dong et al.) — token mask FSM ile production'da 100× hıza kadar çıkıyor, JSON şema garantili çıktı üretiyor.

Yukarıda aynı modele aynı prompt verildi, sadece sampler değişti. Farklar dramatik. Greedy iki cümlede tekrara giriyor; top-p akıcı ama bazen rastgele dağılıyor; min-p denge tutuyor; mirostat uzun pasajda perplexity'i sabit tutuyor.
Bir not: determinism. "temperature=0 koydum, seed verdim, neden iki run farklı çıkıyor?" sorusunu çoğu mühendis sormuştur. Yaygın açıklama — "GPU'daki atomik toplamalar bozuyor" — aslında yanlış; bunu netleştiren, Thinking Machines'in 2025 sonunda yayınladığı yazı oldu. Gerçek şu: LLM forward-pass kernel'lerinin çoğu zaten atomik kullanmıyor ve tek başına çalıştırıldığında bal gibi deterministik. Asıl suçlu batch-invariance eksikliği. Bir kernel'in reduction (toplama) sırası ve stratejisi, batch'in boyutuna ve o batch'te yanında duran diğer isteklerin kompozisyonuna göre değişiyor. Yani senin isteğinin sayısal sonucu, o an "yanında kim varsa"ya göre az da olsa kayıyor — istek aynı, batch farklı, sonuç bit düzeyinde farklı.
> "When a non-batch-invariant kernel is used as part of a larger inference system, the system can become nondeterministic."
Çözüm "batch-invariant kernel" yazmak: reduction sırasını batch'ten bağımsız sabitlemek. Mart 2026'da vLLM, SGLang, TRT-LLM bu kernel'lerin deneysel sürümlerini eklemeye başladı. Hâlâ varsayılan değil — performans bedeli var. Production'da bit-exact determinism istiyorsan, batch_size=1 ya da bu kernel'leri açık tutmak şart.
5. Speculative Decoding — Bedavaya Token
Şimdi inference'ın son üç yıldaki en zarif fikrine geliyoruz. Premise şu: decode memory-bound. GPU'nun tensor core'ları çoğu zaman boş duruyor — bekliyor. Bekleme sırasında bedava hesap var. O bedava hesabı kullansak?
Leviathan ve arkadaşları (Google) 2022 sonunda speculative decoding'i tanıttı. Paper'ın çerçevesi basit: büyük otoregresif modellerden inference yavaştır, çünkü K token üretmek modelin K kez seri çalışması demektir. Speculative decoding ise birkaç token'ı paralel hesaplayarak örneklemeyi hızlandırıyor — hem de çıktıyı hiç değiştirmeden.
Algoritma:
- Küçük, hızlı bir "draft" model M_q al. Onunla γ kadar (mesela 7) token tahmin et — autoregresif, hızlı.
- Büyük "verifier" model M_p'ye tek bir paralel forward pass ile bu γ token'ı ve prefix'i ver. Her pozisyonda M_p'nin gerçek olasılığını al — paralel olarak.
- Her i için, draft'ın önerdiği token'ı kabul et eğer
r_i ~ U(0,1) < p(x_i) / q(x_i)ise. İlk red'de dur. - Red olan pozisyonda M_p'nin düzeltilmiş dağılımından bir token sample et.
Bedava olan kısım şu: M_p'nin tek bir forward'ı, γ+1 pozisyon için sonuç veriyor (positions known). Tek hesap, çok pozisyon. Eğer M_q çoğunlukla doğru tahmin ederse — yani p ve q dağılımı yüksek örtüşse — bedavadan 3-4 token kazanırsın.
Kritik: bu exact. Çıktı dağılımı değişmiyor. Leviathan paper'ı bunun matematiksel kanıtını Appendix A.1'de veriyor. Mekanizmanın doğru adı düzeltilmiş (modified) rejection sampling: kabul edilmeyen pozisyonda düzeltilmiş bir dağılımdan örnekleyerek marjinal dağılımı birebir koruyor (sık sanılanın aksine Metropolis-Hastings değil).
Speedup matematiği de güzel. α = ortalama kabul olasılığı, γ = draft adım sayısı:
E[token / call] = (1 - α^(γ+1)) / (1 - α)
Speedup = (1 - α^(γ+1)) / ((1 - α) × (γc + 1))
c = draft'ın verifier'a maliyet oranı (genelde 0.05). α > c olduğunda kazanırsın. T5-XXL'i T5-Small ile draft edip ENDE çevirisinde 3.4×, CNN/DailyMail özetlemede 3.1× hız. Çıktı bit-exact.
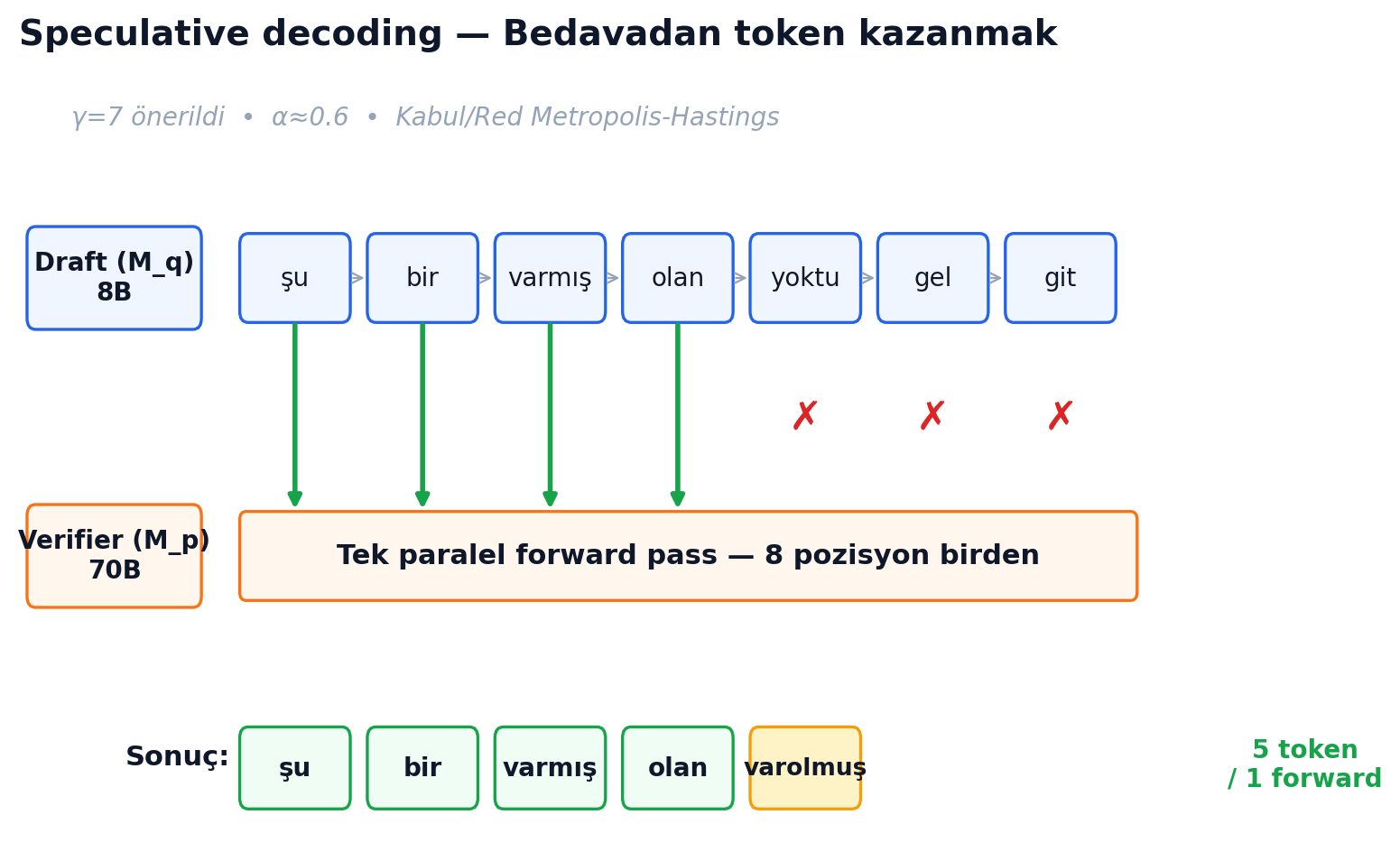
Aynı dönemde DeepMind'dan Chen ve arkadaşları bağımsız olarak aynı tekniği türetti (paper'lar günler arayla çıktı). Onların setup'ı Chinchilla 70B + 4B draft, XSum greedy'de 2.01×, HumanEval nucleus'ta 2.46×. Aynı algoritma, farklı baseline.
Sorun: ya iyi bir draft modelin yoksa? Llama 3 70B için Llama 3 8B fena değil ama 12 katlı bir büyüklük farkı yine de var. Birkaç çözüm geldi:
Medusa (Cai et al. 2024): Ayrı bir draft modelden vazgeç. Aynı backbone üstüne K ekstra head ekle — bunlar K-token-ahead tahmini yapsın. Tree attention ile paralel verify. Medusa-1 Vicuna-7B'de 2.18×, Medusa-2 (joint training) 2.83×, extraction görevlerinde tepe noktası 3.62×.
EAGLE (Li et al. 2024-25): Speculation'ı token seviyesinde değil, feature seviyesinde yap. Son-bir katmandaki feature vektörünü tahmin etmeye çalış, ondan token üret. "Feature uncertainty" framing'i. EAGLE-1 LLaMA2-Chat 70B'de 2.7-3.5×. EAGLE-3 (2025) ise Vicuna 13B'de HumanEval'de 6.47× — γ=4, kabul oranı 7.54 token/call. Pratikteki tepe nokta.
DeepSeek-V3 MTP (Multi-Token Prediction): V3 paper'ında ortaya çıkan bir hibrit fikir — modeli eğitirken aux bir MTP head ile sonraki token'ı da hedefle, training sırasında çoklu-token tahmin yeteneği kazandır. Inference'ta bu head zaten draft görevi yapıyor — ayrı bir draft modele gerek yok. İkinci-token kabul oranı %85-90, TPS 1.8×. Eğitim ve inference iç içe geçmiş bir tasarım.
vLLM 2024 Ekim'den beri üç speculation flavor'ını da destekliyor: draft-based, n-gram (prompt lookup), Medusa/EAGLE/MLPSpeculator. ShareGPT'de 1.5×, CNN/DailyMail özetlemede n-gram ile 2.8×.
Önemli uyarı: yüksek QPS'te speculative decoding yavaşlatabilir. Sebep şu — speculation prefill-benzeri yük getiriyor (paralel verify). Düşük QPS'te bant genişliği boştu, doluyor, kazanıyorsun. Yüksek QPS'te zaten compute-bound'a yaklaşmıştın, ekstra prefill yükü sistemi tepiyor, 0.5-0.7× yavaşlama gözleniyor. vLLM 2026'da bu trade-off'u otomatik yöneten "dynamic speculative decoding" üzerinde çalışıyor.
Thoughtworks'ün Nisan 2026'da paylaştığı production case study: GLM-4.7-Flash + EAGLE-3, prod trafiğinde 1.39× gecikme düşüşü, 1.70× throughput, kabul oranı %40. Paper'daki 6× rakamı laboratuvarın hediyesi; production'da daha mütevazı ama yine de gerçek bir kazanım.
Speculative decoding, "GPU'nun beklemediği zamanlarda da çalışsın" demenin matematiksel adı. Bedava değil tabii — draft modelin maliyeti, doğru ayarlanmış γ, kabul oranı tunelemesi — ama net pozitif çoğu üretimde.
6. Quantization — Bit Cimriliği
Decode memory-bound olduğuna göre, her token için modelden ne kadar az byte okumak zorundaysan, o kadar hızlı gidersin. İşte quantization'ın asıl gerekçesi: kalite değil, bant genişliği.
Önce ölçek. Llama 3 70B BF16'da 141 GB; tek bir A100 80GB'a sığmaz. 4-bit'e inince saf INT4'te (4.0 bpw) ~35 GB, Q4_K_M'de (~4.85 bpw) ~43 GB — ikisi de iki RTX 3090'a rahat sığar. Mesele yalnız bir GPU'ya sığmak değil: ağırlık transferini dörtte bire indirdiğin için decode da ~4× hızlanıyor.
İlk modern quantization paper'larından biri GPTQ (Frantar et al. 2022). One-shot post-training: ikinci-mertebe (Hessian-based) calibration ile satır-satır quantize ediyor. Paper'ın iddiası, 175 milyar parametreli GPT modellerini ~dört GPU-saatte 3-4 bit'e indirebildiği ve doğruluk kaybının sıkıştırılmamış baseline'a göre ihmal edilebilir kaldığı. Asıl çarpıcı cümle ise şu — "allowing us for the first time to execute an 175 billion-parameter model inside a single GPU for generative inference" — 2022'de bu bir devrimdi: INT4'te OPT-175B'yi tek bir A100 80GB'a sığdırıyordu.
AWQ (Lin et al. 2023, MLSys 2024 best paper) bir adım sonraydı. Insight şu: bir LLM'deki ağırlıkların hepsi eşit önemde değil — yalnızca %1'i salient (büyük activation magnitude'leriyle çarpılanlar) ve quantization error'a asıl bunlar hassas. Bu salient channel'ları per-channel scaling ile koruyup geri kalanını agresif quantize edince hata büyük ölçüde düşüyor.
Pratik: LLaMA-65B INT4'te PPL kaybı 3.62 vs 3.55 — neredeyse görünmez. TinyChat ile RTX 4090'da 2.7-3.9× speedup. Jetson Orin'de 3.2-3.5×. AWQ, INT4 server-side inference'in fiili standardı haline geldi.
GGUF llama.cpp'nin formatı — Ağustos 2023'te GGML'in yerine geçti. Block-wise quantization. Q-seviyeleri:
| Quant | Etkin bpw | Llama-3 70B boyutu | Hangi donanım sığar | Kalite notu |
|---|---|---|---|---|
| F16 | 16.0 | 141 GB | 2× A100 80 | baseline |
| Q8_0 | 8.0 | 75 GB | 1× A100 80 | "essentially lossless" |
| Q6_K | 6.56 | 58 GB | 2× RTX 3090 | "near perfect" |
| Q5_K_M | ~5.7 | 50 GB | 1× A100 80 | yüksek kalite |
| Q4_K_M | ~4.85 | 43 GB | 2× RTX 3090 | sweet spot |
| IQ4_XS | 4.25 | 38 GB | 2× RTX 3090 | imatrix, biraz daha küçük |
| IQ3_XXS | 3.06 | 27 GB | 1× RTX 4090 | community magic — tek GPU |
| IQ2_XXS | 2.06 | 19 GB | 1× RTX 3090 | belirgin kayıp ama hâlâ kullanılabilir |
K-quants ve i-quants ayrımı: K-quants block scale + super-block hierarchy ile sabit quantization, i-quants ise importance matrix (training örneklerinden gelen aktivasyon önemleri) ile aynı bpw'de daha düşük PPL veriyor. ikawrakow'un llama.cpp PR #1684 yorumuna göre "the 6-bit quantized perplexity is within 0.1% or better from the original fp16 model."
Topluluğun (r/LocalLLaMA) yıllar içinde damıttığı kural: daha düşük quant'lı daha büyük model neredeyse her zaman daha yüksek quant'lı küçük modeli geçer. Llama-3 70B IQ3_XXS, Llama-3 8B Q8_0'ı geçer. Insight'ı tek cümleye sığdırmak gerekirse: parametre sayısı kapasite, quant bit pratik yokluk vergisi.
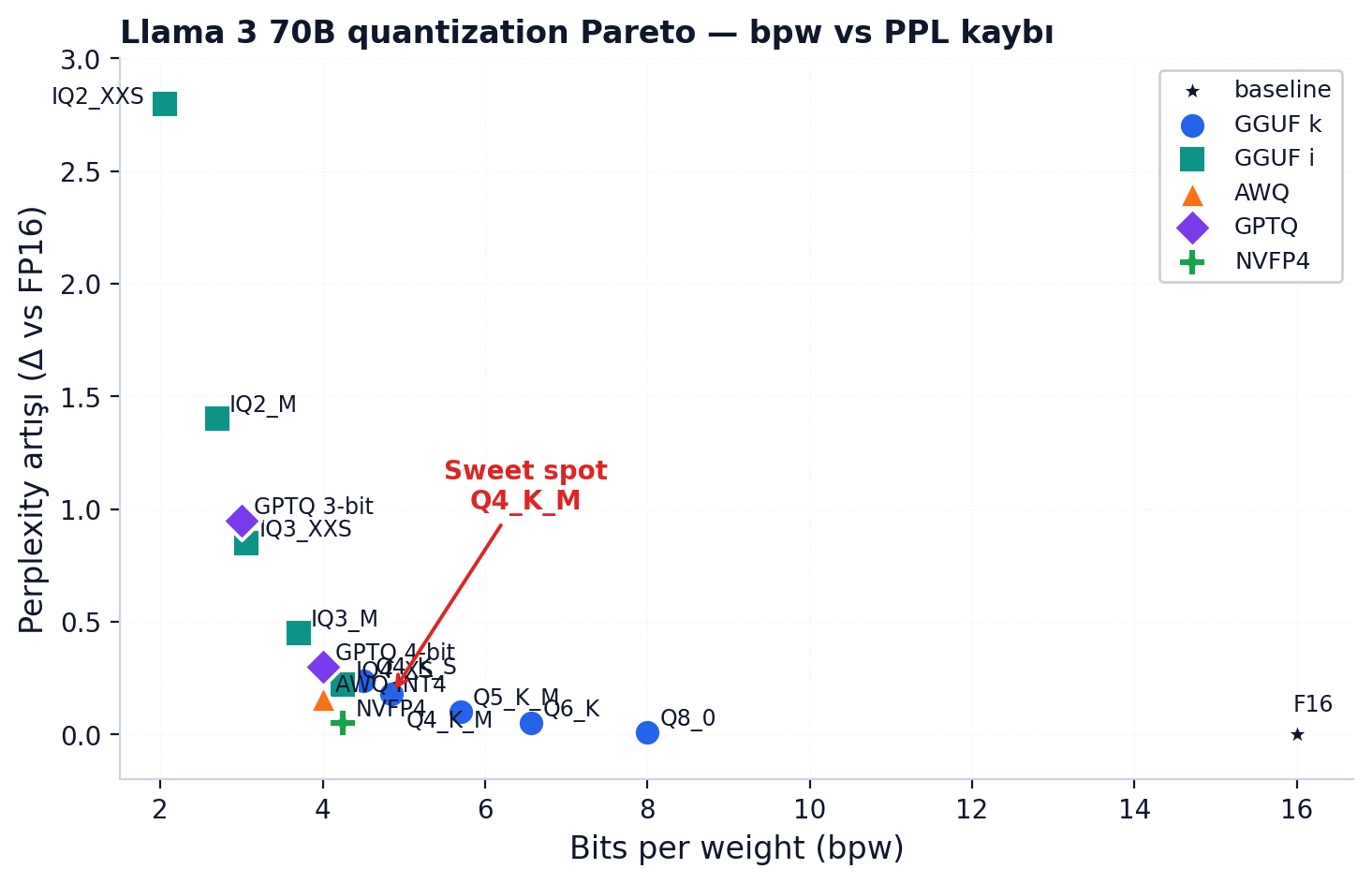
Yukarıdaki Pareto, bir model ailesi için bpw azaldıkça PPL'in nasıl arttığını gösteriyor. Q4_K_M'in neden "sweet spot" olduğu görsel olarak ortaya çıkıyor — daha küçük bpw'lerde eğri sertleşiyor.
FP8 ise donanım katmanı. NVIDIA Hopper'dan beri native: E4M3 (4 exponent, 3 mantissa) forward'da, E5M2 backward'da; NVIDIA Transformer Engine bu formatı kullanıyor. DeepSeek-V3'ün farkı, önceki işlerin aksine — ki onlar gradyan hesabında E5M2'ye düşer — daha yüksek hassasiyet için E4M3'ü tensörlerin genelinde benimseyen ilk büyük açık model olması.
Pratik etkisi: vLLM 2026 itibariyle FP8 KV cache ve FP8 weights kombinasyonuyla Llama 3 8B'de 2.7× throughput, 70B'de 1.8× veriyor. "With FP8, vLLM deployments may receive up to a 2x reduction in latency with minimal accuracy degradation."
Blackwell'in NVFP4'ü ise 2025'in en agresif adımı: 4-bit floating point (E2M1 element) + iki seviyeli ölçekleme — ince taneli bir per-block E4M3 scale ve ikinci seviye per-tensor FP32 scalar. NVIDIA'ya göre ultra-düşük hassasiyette model doğruluğunu ayakta tutan tam da bu iki-seviyeli strateji.
DeepSeek-R1'in NVFP4 PTQ benchmark'ı AIME 80.0 vs orijinal 80.0 — sıfır kayıp. NVFP4 GB200'de H200'e karşı kullanıcı-başı gecikme 2.5× düşüyor.
KV cache quantization ayrı bir hikaye — KIVI (2024) key cache'i per-channel, value cache'i per-token quantize ediyor (asimetrik tasarım, çünkü ikisinin dağılım profilleri farklı: key'lerde belirgin kanal-yönlü aykırılıklar var, value'larda yok). 2-bit KV cache, Llama-2-7B CoQA'da 63.05 vs orijinal 63.88 — bedavaya 4× batch. vLLM 2026 FP8 KV cache desteğini production'a aldı.
Tek cümlelik özet: quantization yalnız bellek kazancı değil — decode hızının primer kaynağı. Bant genişliği primer'sa, her bit'in geri ödemesi var.
7. Donanım Katmanı — H100'den Cerebras'a
Tüm yazılım optimizasyonu bir noktada donanımın limiti ile karşılaşıyor. 2026'da inference donanım manzarası beş ayrı kategoriye düşüyor.
NVIDIA Hopper / Blackwell: H100 hâlâ baseline. H200 aynı çip ama daha geniş ve daha hızlı bellekle gelir; darboğaz neredeyse her zaman bellek olduğu için uzun-bağlam inference'in patron çipi odur. Blackwell B200 ile asıl sıçrama FP4 (9 PF dense / 18 PF sparse) — düşük hassasiyetli inference'i doğrudan donanıma gömüyor. GB200 NVL72 ise tek bir GPU değil, bir sistem: 72 B200 + 36 Grace CPU'yu 13.4 TB unified memory'de NVLink'le tek havuzda birleştiren bir rack. NVIDIA bu konfigürasyonda Llama 3.1 405B server'da H200'e karşı 30× sistem-seviyesi throughput rapor ediyor. (Çiplerin ham bellek/bant genişliği rakamları için aşağıdaki tablo.)
AMD MI300X / MI325X: AMD'nin asıl kozu bellek kapasitesi — MI325X bu kuşakta hem H200'ü hem B200'ü bellek miktarında geçiyor (tabloya bak). Bu yüzden capacity-heavy işler için (büyük modeli tek GPU'da tutmak, uzun bağlam) cazip. Yazılım ekosistemi (ROCm) olgunlaşıyor ama hâlâ CUDA kadar geniş değil.
Google TPU: v5p 95 GB HBM, Trillium (v6e) yeni nesil. Google Cloud'a bağlı, dış dünyada doğrudan satın alınamıyor. Anthropic Trillium'u 2025'ten beri yoğun kullanıyor — Claude Sonnet/Opus inference'inin sessiz omurgası.
Cerebras WSE-3: Wafer-scale çip; bütün hüner belleğin yerinde. Ağırlıklar HBM'de değil, çipin kendi üstündeki SRAM'inde duruyor — bant genişliği bu yüzden HBM'lerinkinin binlerce katı (pazarlama "7,000×" diyor; H100'e karşı bizim ölçtüğümüz ~6,268×). Sonuç pratikte görülüyor: Cerebras Inference Llama 3.1 70B'yi 2024 Ağustos'unda saniyede 450 token, Mart 2025'te 2,100 token/s servis etti — sıradan bir H100 cluster'ının 5-10× üstü.
Groq LPU: Yine SRAM-based, ama farklı tasarım — yüzlerce çip federate. Düşük gecikme garantili (deterministik routing). Llama 70B'de saniyede 500+ token. Tek kullanıcılı interaktif inference için bir start-up'ın hayalini gerçekleştiriyor.
Apple Silicon M3/M4 Ultra: Mac Studio'nun kozu da kapasite — 512 GB'a kadar unified memory, DeepSeek R1 671B'yi Q4_K_M'de (~404 GB) tamamen RAM'e sığdırmaya yetiyor: saniyede ~18 token, hem de 200 W'ın altında. Hobbyist, 2025'te "frontier-boy bir modeli evde koşturuyorum" diyebildiği ilk dönemi yaşıyor. MLX framework Apple Silicon için optimize; llama.cpp + Ollama + LM Studio üçlüsü standart.
| Çip | Memory | Bant genişliği | Use case |
|---|---|---|---|
| H100 SXM | 80 GB HBM3 | 3.35 TB/s | training + inference referans |
| H200 SXM | 141 GB HBM3e | 4.8 TB/s | uzun-bağlam inference |
| B200 (per-GPU) | 192 GB HBM3e (bulutta ~180 kullanılabilir) | 8 TB/s | FP4 inference, training |
| MI325X | 256 GB HBM3e | 6 TB/s | capacity-heavy |
| WSE-3 | 44 GB SRAM | 21 PB/s | latency rekoru |
| Groq LPU | yüzlerce MB SRAM | ~80 TB/s on-chip | düşük gecikme, çok çip |
| M3 Ultra | 512 GB unified | >800 GB/s | local hobbyist 600B+ MoE |
Bu tablodan iki çıkarım: (1) bellek miktarı + bant genişliği inference'in primer iki ekseni, FP4 throughput sonra geliyor. (2) "Tek doğru çip" yok — workload'a bağlı. Frontier-API için Blackwell, capacity için MI325X, latency rekoru için Cerebras/Groq, local için M3 Ultra.
Edge LLM ise ayrı bir dünya. Apple Intelligence ~3B on-device + Private Cloud Compute server-side melezi. iPhone 17'de cihazda akan model, ağır işlerde Apple'ın PCC server'larına atlıyor — gizlilik kanıtlanabilir biçimde korunarak. Google'ın Gemini Nano'su Pixel ve Chrome'da yerleşik. Microsoft'un Phi-3.5-mini / Phi-4-mini ailesi 3.8B parametreyle 14B-class kaliteyi taşımayı hedefliyor. Meta'nın Llama 3.2 1B/3B'si edge için optimize. Trend net: 2027'ye girerken çoğu sıradan asistan görevinin cihazda kalması bekleniyor — cloud sadece ağır reasoning ve uzun bağlam için.
Cihazdaki ~3B modelle cloud'daki Opus 4.7 arasındaki gecikme farkının yarısı buradan geliyor — donanımdan. Yerel RAM, yerel hesap, kuyruksuz. Bulutta yüzlerce milyar parametre, çok-tenant queue, paylaşılan kaynaklar. Donanım farklı, fiziği farklı, sonuç farklı.
8. 2026 Pricing — Kim Ne Kadar?
Bütün bu mühendislik tek bir piyasa rakamına indirgeniyor: $ / 1M token. artificialanalysis.ai'ın leaderboard'una 2026-05-25 itibariyle baktığımızda manzara şu:
| Model | Sağlayıcı | $/M girdi | $/M çıktı | Kalite | t/s |
|---|---|---|---|---|---|
| GPT-5.5 (high) | OpenAI | 5.00 | 30.00 | 59 | 68 |
| Claude Opus 4.7 (max) | Anthropic | 6.25 | 25.00 | 57 | 48 |
| Claude Sonnet 4.6 | Anthropic | 3.00 | 15.00 | 44-52 | 44-54 |
| Claude Haiku 4.5 | Anthropic | 1.00 | 5.00 | 31-37 | 91-95 |
| Gemini 2.5 Pro | 1.25 | 10.00 | 35 | 138 | |
| Gemini 3.1 Pro Preview | 2.00 | 12.00 | 57 | 136 | |
| Gemini 3.5 Flash | — | — | 55 | 221 | |
| DeepSeek V4 Pro | DeepSeek | 0.43 | 0.87 | 39-52 | 38-46 |
| DeepSeek V4 Flash | DeepSeek | — | — | 36-47 | 113-120 |
| Qwen3.7 Max | Alibaba | — | — | 57 | 197 |
| Mistral Large 3 | Mistral | — | — | 23 | 49 |
| Llama 4 Maverick | Meta (provider) | — | — | 18 | 110 |
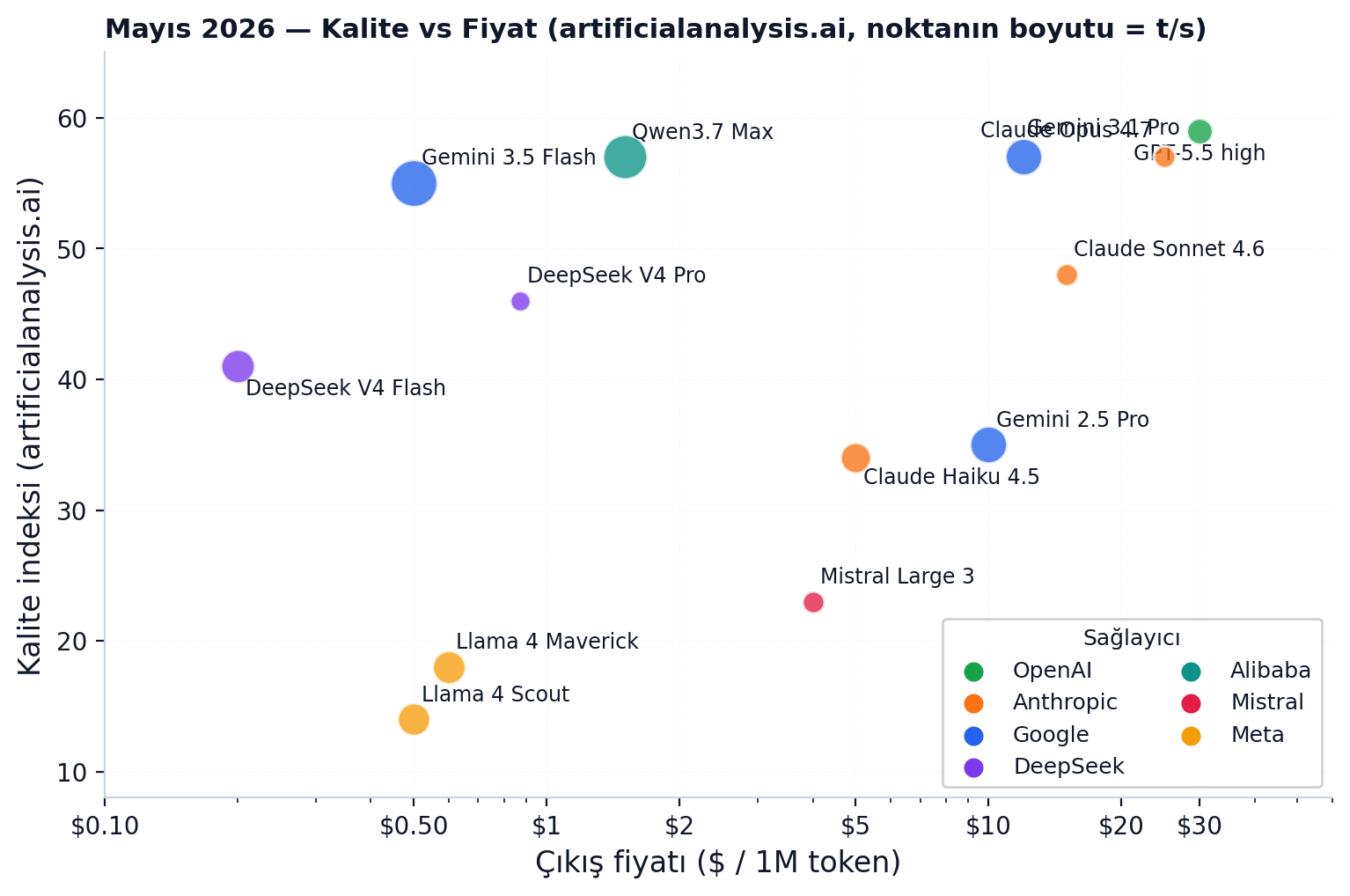
Scatter'da iki şey hemen göze çarpıyor:
1. Frontier kalite çok pahalı kalmaya devam ediyor. Tablonun en üst iki satırı — GPT-5.5 high ve Opus 4.7 — "quality 57+" bölümünü neredeyse tek başlarına tutuyor; token fiyatları da kategorinin en tepesinde. Ucuzlamadılar; ama on yıl önceki dolarla kıyaslanınca yine de ucuz.
2. Open-weight çağı fiyatı sıfıra yaklaştırdı. DeepSeek V4 Pro kalite 39-52 bandında — ama tablodaki fiyatlarını GPT-5.5'inkiyle oranlayınca fark çarpıcı: girişte ~12×, çıkışta ~34× daha ucuz. ("On katı" demek aslında çıkıştaki asıl farkı gizliyor.) Frontier'a yakın kalitedeki işi, frontier fiyatının küçük bir kesrine çıkarabiliyorsun. Gemini Flash, Qwen3.7 Max gibi modeller "her gün her ölçekte kullanılabilir" segmentini yaratıyor.
Hız tarafında Cerebras, Groq, SambaNova ayrı bir kategori. artificialanalysis.ai'ın provider leaderboard'unda Cerebras Llama 3.1 8B'yi 2,349 t/s üretiyor. Groq gpt-oss-20B'yi 928 t/s. SambaNova gpt-oss-120b'yi 722 t/s. Sıradan H100 cluster'ı 100-150 t/s sınırında — bu "fast inference" sağlayıcıları bambaşka bir Pareto noktasında.
İlginç bir kategori daha: diffusion text models. Inception'un Mercury 2'si artificialanalysis leaderboard'da 900 t/s rapor ediliyor. Token üretimini sıralı yerine paralel yapan diffusion decoding mimarisi — 2025 sonlarında ortaya çıkıp tartışılan bir yön. Frontier kalitede henüz değil ama "kaba taslak için 900 t/s" gibi use case'lerde rekabetçi.
Pricing landscape'in ana mesajı şu: token başına fiyat 2024-2025'te frontier'da %80'e yakın düştü, mid-tier'da neredeyse sıfıra yaklaştı. Bu düşüş "sektör batıyor" değil — algoritmik (FP8, quantization, speculative) + donanım (H100→H200→B200) + serving (vLLM/SGLang/TRT-LLM) optimizasyonlarının kümülatif sonucu. Talep çok daha hızlı büyüdüğü için ciro artıyor; birim ekonomi düzeliyor.
Bir önceki yazıda Nathan Lambert'ten alıntılamıştım: "Training strong AI models is a relatively small cost compared to large-scale deployments." Bu yazı o cümleyi sayılarla taşlaştırdı.
9. Yaygın Yanlış Anlamalar
> Hızlı liste > > - "Daha çok GPU = daha hızlı inference." Yarı doğru. Modeli kopyalayıp bağımsız replika olarak eklersen yalnızca paralel istek kapasiten (throughput) artar; tek bir kullanıcının gecikmesi düşmez. Ama Tensor Parallelism bambaşka: ağırlığı N GPU'ya bölersin, her GPU token başına ağırlığın 1/N'ini paralel okur — memory-bound decode'da bu, tek-stream gecikmeyi NVLink-bound rejimde neredeyse lineer düşürür (all-reduce maliyetiyle azalan getiri). Düşük-gecikme serving'in TP=8 koşmasının sebebi tam budur. > - "FP8 / INT4 kalite kaybeder." Düşük-bit quantization 2026'da neredeyse free lunch. DeepSeek-R1 NVFP4 AIME 80.0 vs orijinal 80.0. Q4_K_M PPL kaybı genelde <%1. Sweet spot var, agresif düşülürse (IQ2) kayıp belirginleşir. > - "Speculative decoding kaliteyi düşürür." Tam tersine, Leviathan ve Chen paper'larının ana iddiası bit-exact aynı dağılım. Sadece hızlandırma. > - "temperature=0 ve seed yeterli — çıktı deterministik olur." Batched serving'de değil. Batch içindeki diğer isteklerin uzunluğu ve kompozisyonu floating-point reduction sırasını değiştirip sonucu az da olsa kaydırabiliyor (kernel'ler tek tek deterministik olsa bile). Bit-exact istiyorsan batch-invariant kernel + batch=1 gerek. > - "Cerebras ve Groq tüm kullanım için H100'ü geçti." Pricing modelleri ve workload uyumluluğu farklı. Tek-kullanıcı interaktif latency'de evet rekortmen; multi-tenant throughput ve maliyet/token'da NVIDIA hâlâ ezberi. > - "vLLM en hızlı, başka frameworke gerek yok." 2026'da vLLM, SGLang, TRT-LLM ve TGI v3 Pareto frontier'ı paylaşıyor. Workload'a göre tercih. > - "Local model = ücretsiz." GPU'nun amortismanı ve elektriği var. RTX 4090'da Llama 70B Q4 koşturmak amortize edilince DeepSeek API'sinden zorlukla ucuza geliyor. Local'in asıl satın aldığın şey gizlilik ve bağımsızlık.
10. Kapanış
Açılışta H100'ün boş durduğunu söyledim. Saniyede 989 trilyon işlem yapabilen bir çip, en yaygın görevinde silikonunun büyük çoğunluğunu boşa harcıyordu. Sebep tek satırdı: ulaşım. Hesap değil, ulaşım.
Bu yazı o boşluğun haritası: prefill ile decode'un farklı fizikleri, KV cache'in OS'tan ödünç aldığı paging, continuous batching'in GPU takvimini yeniden çizmesi, speculative decoding'in beklemeyi tahmine çevirmesi, quantization'ın bant genişliğini yarıya indirmesi, ve nihayet donanım katmanının on yıllık silikon yarışı. Hepsi tek bir 42 milisaniyenin içinde başka iş yapabilmek için yazılmış.
Frontier kalitenin token başına maliyeti son bir yılda %80'e yakın düştü — sebebi yeni bir model değil, bu katmanların hep birlikte sıkışması. Sektörün asıl yarışı artık eğitimde değil, silinmiş bekleme süresinde.
Dört yazılık dizi tamamlandı. İlkinde kavramları çevirdik, ikincide mimariyi söktük, üçüncüde inşaatı (eğitimi) gezdik, dördüncüde modeli çalıştırdık. Eğitim "ne biliyor"u, mimari "nasıl düşünüyor"u, fine-tuning "neyi söylemez"i, ve inference "nasıl ulaşıyor"u öğretti.
Sevdiğim bir benzetme var: modeli eğitmek silahı yapmak, inference ise onu kullanmak. Modelin gerçek değeri ikincide — kullanımda — ortaya çıkıyor; sektörün ekonomisi de artık bunun üzerine kurulu.
Ödev: bir LLM API çağrısı yap (OpenAI, DeepSeek veya yerel bir vLLM endpoint'i fark etmez). Streaming aç. İlk token gelmeden geçen süre ile sonraki token'lar arası süreyi ayrı ayrı ölç. İkisi arasındaki farkı görünce, bu yazının tüm geri kalanı yerine oturuyor — birincisi prefill, ikincisi decode, ve modern inference mühendisliğinin tek cümlelik özeti: ikisini ayrı düşün.
Dörtleme şimdilik tamam. Bir sonraki yazıda satır satır kendi mini-inference engine'imizi yazalım — KV cache yönetimi, continuous batching scheduler'ı, basit bir speculative decoding döngüsü, Python ve birkaç yüz satır CUDA ile.
Kaynakça
Birincil paper'lar
- Kwon et al. 2023, Efficient Memory Management for Large Language Model Serving with PagedAttention (SOSP 2023) — arxiv.org/abs/2309.06180
- Yu et al. 2022, Orca: A Distributed Serving System for Transformer-Based Generative Models (OSDI 2022) — usenix.org/conference/osdi22/presentation/yu
- Zheng et al. 2024, SGLang: Efficient Execution of Structured Language Model Programs (NeurIPS 2024) — arxiv.org/abs/2312.07104
- Leviathan, Kalman, Matias 2023 (Google), Fast Inference from Transformers via Speculative Decoding (ICML 2023) — arxiv.org/abs/2211.17192
- Chen et al. 2023 (DeepMind), Accelerating Large Language Model Decoding with Speculative Sampling — arxiv.org/abs/2302.01318
- Cai et al. 2024, Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads — arxiv.org/abs/2401.10774
- Li et al. 2024-25, EAGLE / EAGLE-2 / EAGLE-3 — arxiv.org/abs/2401.15077
- DeepSeek-AI 2024, DeepSeek-V3 Technical Report (MTP, FP8) — arxiv.org/abs/2412.19437
- Frantar et al. 2022, GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers — arxiv.org/abs/2210.17323
- Lin et al. 2023, AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration (MLSys 2024 best paper) — arxiv.org/abs/2306.00978
- Xiao et al. 2022, SmoothQuant — arxiv.org/abs/2211.10438
- Dettmers et al. 2022, LLM.int8() — arxiv.org/abs/2208.07339
- Liu et al. 2024, KIVI: Tuning-Free Asymmetric 2-bit KV Cache Quantization — arxiv.org/abs/2402.02750
- Dao et al. 2022, FlashAttention — arxiv.org/abs/2205.14135
- Sheng et al. 2023, S-LoRA: Serving Thousands of Concurrent LoRA Adapters — arxiv.org/abs/2311.03285
- Holtzman et al. 2019, The Curious Case of Neural Text Degeneration — arxiv.org/abs/1904.09751
- Nguyen et al. 2024, Min-p Sampling — arxiv.org/abs/2407.01082
- Dong et al. 2024, XGrammar: Flexible and Efficient Structured Generation Engine — arxiv.org/abs/2411.15100
Sektör analizleri ve mühendislik yazıları (2024-2026)
- Databricks, LLM Inference Performance Engineering: Best Practices — databricks.com/blog/llm-inference-performance-engineering-best-practices
- vLLM ekibi, PagedAttention launch — vllm.ai/blog/2023-06-20-vllm
- vLLM, v0.6 performance update — vllm.ai/blog/2024-09-05-perf-update
- vLLM, V1 alpha release — vllm.ai/blog/2025-01-27-v1-alpha-release
- vLLM, Speculative decoding — vllm.ai/blog/2024-10-17-spec-decode
- LMSYS, SGLang launch (RadixAttention) — lmsys.org/blog/2024-01-17-sglang
- NVIDIA, Blackwell MLPerf Inference v5.0 — developer.nvidia.com/blog/nvidia-blackwell-delivers-massive-performance-leaps-in-mlperf-inference-v5-0
- NVIDIA, NVFP4: low-precision inference — developer.nvidia.com/blog/introducing-nvfp4-for-efficient-and-accurate-low-precision-inference
- Cerebras, Inference 3× faster (2025) — cerebras.ai/blog/cerebras-inference-3x-faster
- Apple, Apple Foundation Models 2025 tech report — machinelearning.apple.com/research/apple-foundation-models-tech-report-2025
- Thinking Machines, Defeating Nondeterminism in LLM Inference — thinkingmachines.ai/blog/defeating-nondeterminism-in-llm-inference
- artificialanalysis.ai leaderboard — artificialanalysis.ai/leaderboards/models
Pratik araçlar
- vLLM — github.com/vllm-project/vllm
- SGLang — github.com/sgl-project/sglang
- TensorRT-LLM — github.com/NVIDIA/TensorRT-LLM
- TGI — github.com/huggingface/text-generation-inference
- llama.cpp — github.com/ggml-org/llama.cpp
- AWQ — github.com/mit-han-lab/llm-awq
- XGrammar — github.com/mlc-ai/xgrammar
- Outlines — outlines-dev.github.io/outlines
Finis