Akrabamla telefondaydım, "ChatGPT denen şey ne ya, oğul, sen bunu biliyorsundur" dedi. Anlatmaya başladım — token şuydu, parametre buydu, transformer şöyle çalışıyordu — yarım dakika sonra hattaki ses "dur, kestim seni, bir Türkçe konuş" dedi. Telefonu kapattıktan sonra on dakika boyunca aynaya baktım: ben miydim jargon kalkanının arkasına saklanan, yoksa konu mu gerçekten bu kadar kötü anlatılıyordu? İkisi de. 2026'da "AI" kelimesinin altındaki şey, açıklamaya çalışmadığında basit, açıklamaya çalıştığında saçma görünüyor.
Bu yazı, o on dakikalık aynaya bakışın ürünü — akrabama anlatmaya çalıştığım her şeyin, hiçbir önceki bilgi gerektirmeden, sıfırdan baştan yazılmış hali. Sonunda ne olacak: bir LLM tartışmasında "hadi bakalım" diyebileceksin. Daha iyisi: hangi cümlenin satılık olduğunu, hangisinin gerçekten mimariyle ilgili olduğunu ayırt edebileceksin.
Güncellik notu (Mayıs 2026): Bu yazıdaki model isimleri, sürümler ve fiyatlar bu tarihteki haldir ve çok hızlı bayatlar — modeller neredeyse her ay, fiyatlar daha da sık değişir. Rakamları kesin doğru kabul etme; aşağıda her biri için resmi sayfaya bağlantı bıraktım, bir karara dayandırmadan önce oradan teyit et. Burası bir anlık fotoğraf, canlı bir fiyat listesi değil.
LLM Aslında Ne Demek?
LLM dediğimiz şey aslında üç kelimelik bir reklam: Large Language Model, Türkçesi Büyük Dil Modeli. Sıralayalım, çünkü her kelimesi yalan olmasa da kafa karıştırıyor:
- Dil: insan dili. Türkçe, İngilizce, kod, emoji — ne yazıyorsan.
- Model: matematiksel bir tahmin makinesi. "Şu giriyor, şu çıkıyor" diye bir kalıp öğrenmiş bir şey.
- Büyük: gerçekten büyük. Milyarlarca sayı barındıran.
Daha somut: bir LLM, bir sonraki token'ı tahmin etmek üzere eğitilmiş dev bir sinir ağı. "Bugün hava çok..." yazsam, modelin kafasındaki olasılık tablosunda güzel %42, soğuk %18, patates %0.00001 gibi değerler var. En olası gelecekleri seçerek (veya rastgele örnekleyerek) cümle kuruyor. Hepsi bu.
ChatGPT, Claude, Gemini, Grok — hepsi aynı temel fikri farklı şirketin pazarlamasıyla satıyor. İçeride aşağı yukarı aynı şey dönüyor.
"Yani tek yaptığı bir sonraki kelimeyi tahmin etmek mi?" — evet, gerçekten. Mucize gibi görünen her şey (kod yazması, fıkra anlatması, matematik yapması) o tahmin probleminin yeterince iyi çözüldüğünde kendiliğinden ortaya çıkan davranışlar. Buna emergent behavior (beliren davranış) deniyor ve hâlâ tam olarak anlaşılmış değil.
Büyük resim. Bundan sonraki bölümlerin her biri tek bir zincirin halkası. Haritayı baştan görelim, sonra tek tek açarız:
Metin → [Tokenizer] → token'lar → [Embedding] → vektörler
→ [Transformer katmanları × N: attention] → olasılık dağılımı
→ bir sonraki token'ı seç → (tekrarla) → Cevap
Token, embedding, parametre, attention, context window... hepsi bu akışın bir yerinde. Şimdi sırayla.
Token Nedir?
Modelin kafasında "kelime" diye bir şey yok. Token var. Token, modelin görebildiği en küçük parça. Bazen tam kelime, bazen parça, bazen tek harf.
Bunu ilk öğrendiğimde tuhaf bir hayal kırıklığı yaşamıştım — "yani model kahvaltı kelimesini gerçekten bir bütün olarak görmüyor mu?" Görmüyor. Onun için kah ve valtı iki ayrı zar.
İlk önemli sezgi: aynı kelime farklı dillerde farklı sayıda token olur. (Aşağıdaki sayılar GPT-4'ün tokenizer'ı [cl100k_base] içindir ve örnek amaçlıdır — her model kendi tokenizer'ını kullanır, bölünme ve sayılar modele göre değişir.)
- İngilizce
breakfast→ genelde 1 token - Türkçe
kahvaltı→ genelde 2 token (örn.kah+valtı) çekoslovakyalılaştıramadıklarımızdanmışsınızcasına→ ~17 token
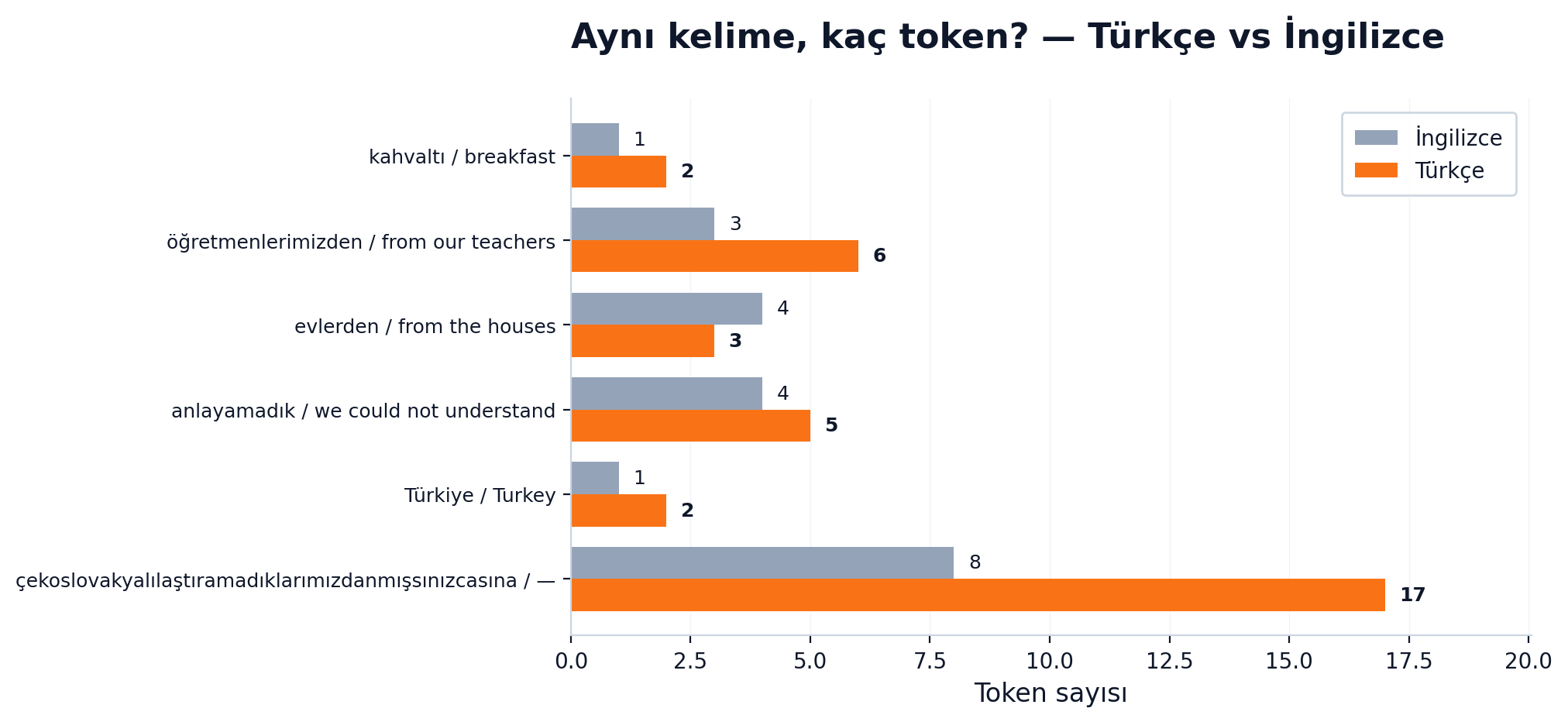
Bu bir tasarım kusuru değil, istatistiksel bir gerçek. Tokenizer (token'a bölen algoritma) eğitim verisindeki en sık görülen kalıpları birleştirerek vocabulary (sözlük) oluşturur. İngilizce internette çok daha bol olduğu için İngilizce kelimeler tek parça halinde yer alıyor. Türkçe gibi eklemeli (agglutinative) dillerde her ek modelin gözünde bir çıkıntı, ve agresif şekilde parçalanıyor.
Niye umrunda olsun? Üç yerde cebine vuruyor:
- Para: API'ler token başına faturalandırır. Mayıs 2026 itibarıyla GPT-5.5 kabaca $1.75 / 1M giriş, $14 / 1M çıkış; Claude Opus 4.7 $5 / $25 (token başına) — ama bu rakamlar sık değişir, güncelini OpenAI ve Anthropic fiyat sayfalarından doğrula. Geçen ay bir Türkçe RAG sistemi için Claude faturamı hesapladım — aynı içerik, aynı sorular — İngilizce versiyondan 2.3 kat daha pahalıya çıkıyordu. Tokenizer'la barışık olmayan dil konuşmanın gizli vergisi bu.
- Hız: Daha çok üretilen token = daha çok forward pass = daha yavaş cevap. (Girdideki token'lar tek seferde paralel işlenir — buna "prefill" denir; "her token bir forward pass" kuralı asıl cevabın üretildiği aşama için geçerli.)
- Context window: 1M'lik pencereye İngilizce'den daha az Türkçe metin sığar.
- Kalite:
evlerdenkelimesiev + ler + dendiye temiz bölünse model çoğul ve durum bilgisini koruyabilir. Saçma yerden parçalanırsa bilgi kaybediliyor.
Kullanılan başlıca tokenizer algoritmaları:
| Algoritma | Kim kullanıyor |
|---|---|
| BPE (Byte-Pair Encoding) | GPT-2/3/4/5, Llama, Mistral, Gemma, Qwen — fiilen standart |
| WordPiece | BERT (artık eski) |
| SentencePiece | Llama 1/2, Gemma, T5 |
| tiktoken | OpenAI'ın hızlı BPE implementasyonu (Rust) |
Vocab boyutları kabaca şöyle: GPT-4 ~100K, GPT-5 ~200K, Llama 3 ~128K. Büyük vocab = daha az parçalanma ama daha şişman embedding tablosu — bedava değil yani.
2026'da ilginç bir gelişme var: tokenizer'sız modeller. Meta'nın Byte Latent Transformer (BLT) ham byte üzerinde çalışıyor, sabit bir vocab'a ihtiyaç duymuyor. (Üzerine çıktığı söylenen "Fast BLT"nin inference bant genişliğini %50'den fazla azalttığı iddia ediliyor — bu rakamı bağımsız teyit edemedim, üretici iddiası olarak oku.) Türkçe gibi düşük temsil edilen diller için uzun vadede iyi haber.
Kendi metnine kaç token gittiğini merak ediyorsan, platform.openai.com/tokenizer'a yapıştırıp bak. Faturanı yazdıracak şeyi gözünle görmüş olursun.
Parametre — "Ayar Düğmeleri"
Modelin içinde parametre denen şeyler var. Her parametre, ağdaki bir bağlantıya iliştirilmiş küçük bir sayı (bir ağırlık). Modeli eğitmek, milyarlarca düğmeyi azar azar çevirip cevapları daha az yanlış hale getirmek demek.
Şöyle düşün: 7 milyar düğmeli bir radyo var, ve sen birine "doğru istasyona gelene kadar çevirmeye devam et" diyorsun. Eğitim algoritması (gradient descent) o sabırlı zavallı. Trilyonlarca token gösteriyorsun, her yanlış tahminde düğmeleri usulca düzeltiyor. Aylar sonra düğmeler dilin istatistiksel kalıplarını öğrenmiş halde donuyor.
Niye milyarlarca? Çünkü transformer mimarisi katmanlardan oluşuyor ve her katmandaki "nöron"lar diğerleriyle ağırlıklarla bağlı. Kabaca: parametre ≈ 12 × katman × gizli boyut². Sayılar uçuyor.
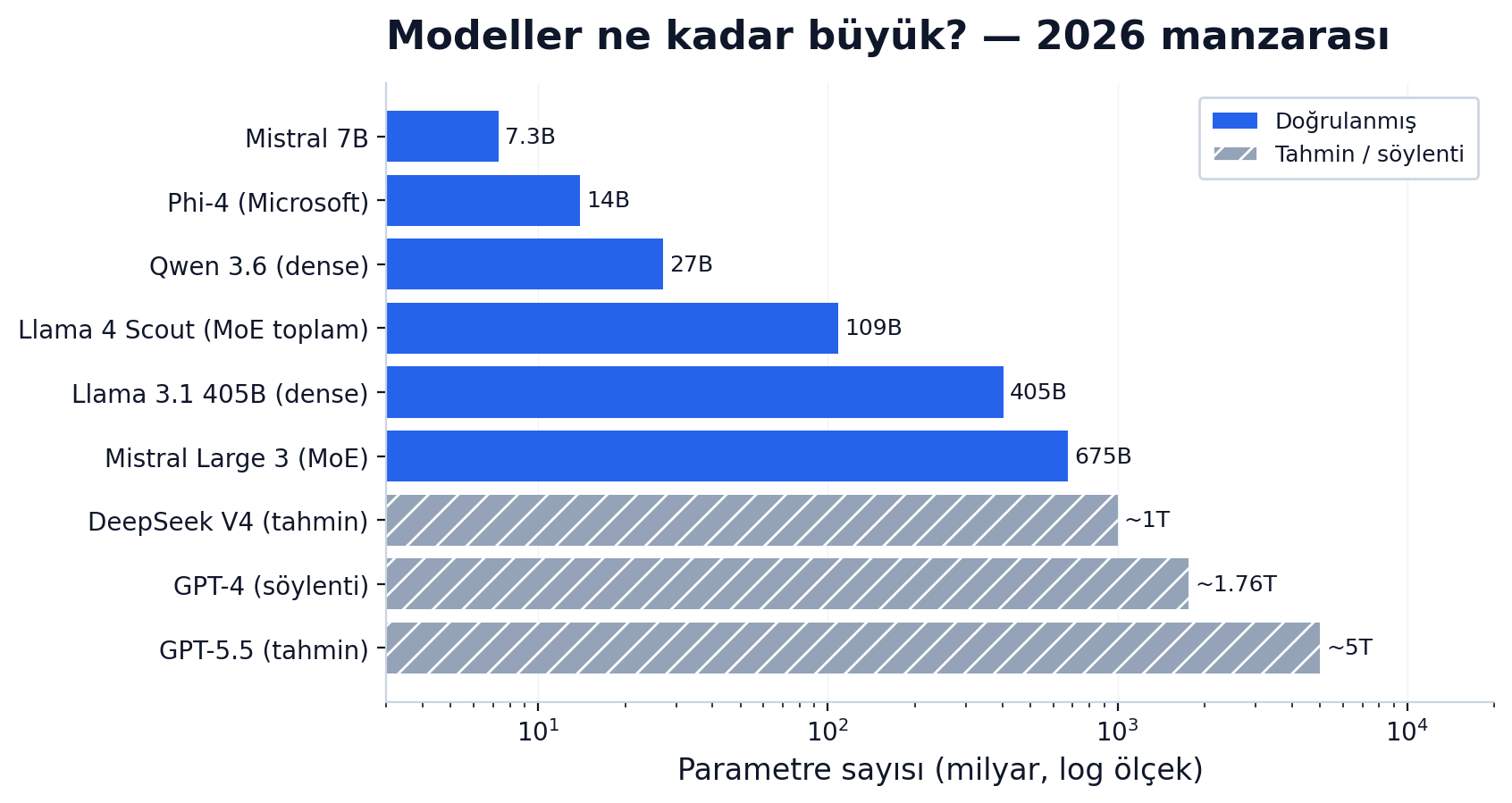
Mayıs 2026 itibarıyla, ölçeği göstermesi için birkaç temsilî örnek (tam liste aşağıda "Hangisi Ne?" bölümünde):
- GPT-4 (2023): ~1.76 trilyon olduğu söyleniyor (MoE). Yeni nesil (GPT-5/5.5, Claude Opus 4.x) sayılarını ise kimse açıklamıyor.
- Llama 3.1 405B: 405 milyar, dense (MoE değil) — tek tip uçta örnek.
- Llama 4 Scout (Nisan 2025): 109B toplam / 17B aktif, MoE — "büyük ama her token'da ucuz çalışan" mantığı.
- DeepSeek V4 (Nisan 2026): ~1T civarı tahmin, MoE.
- Phi-4 (14B) / Mistral 7B: küçük uç — dizüstüne sığan, iyi eğitilmiş modeller.
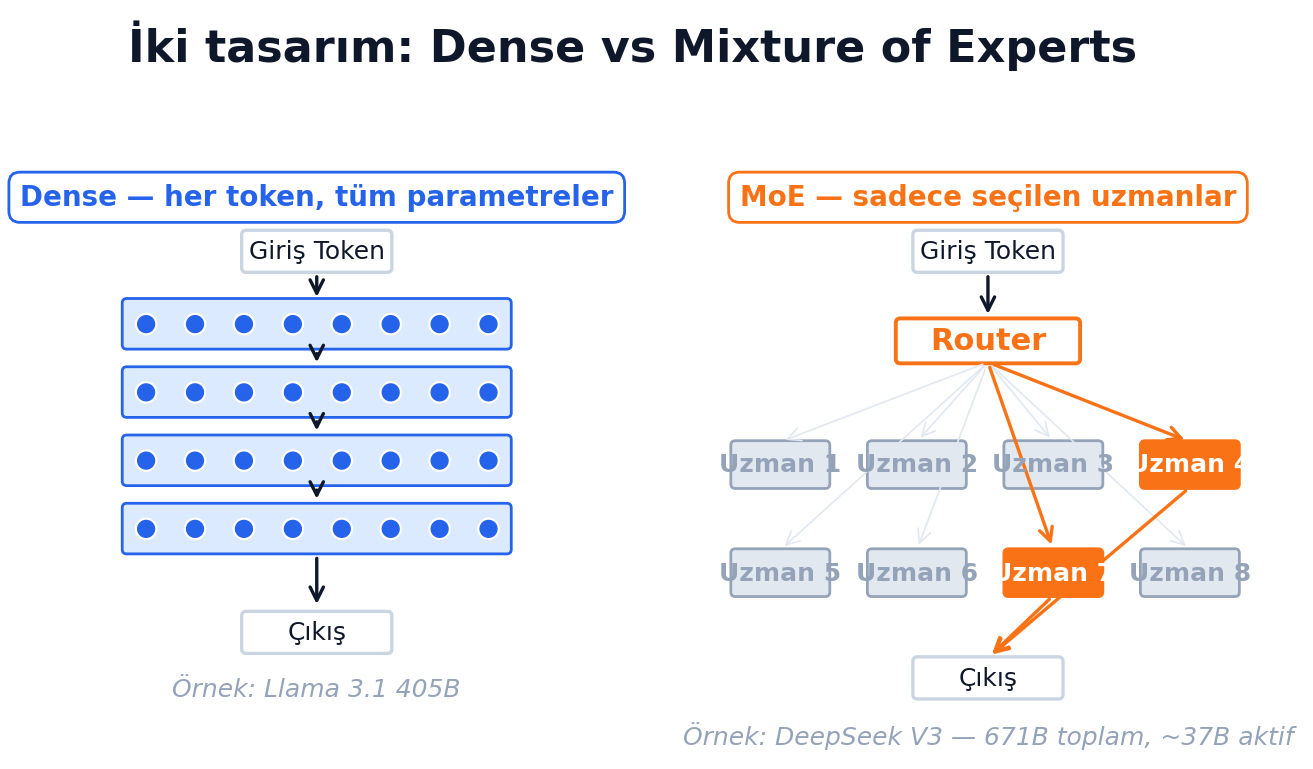
Dense vs MoE
İki tasarım var:
Dense (yoğun): her token için bütün parametreler çalışır. Llama 3.1 405B böyle.
Mixture of Experts (MoE): model içinde çok sayıda "uzman" alt-ağ var. Her token için bir yönlendirici (router) sadece birkaçını seçer. DeepSeek V3 671 milyar parametreye sahip ama her token'da sadece ~37 milyarlık iş yapar. Yani dev bir kütüphanen var ama her soruda sadece 1-2 uzmana danışıyorsun. Inference ucuz; karşılığında eğitim cehennemi.
Scaling Laws
Chinchilla araştırması (DeepMind, 2022) şu sezgiyi getirdi: parametre kadar veri de önemli. Compute-optimal kural: her parametre için ~20 eğitim token'ı. Eski dev modeller (GPT-3) verisini yeterince yememişti. Daha küçük ama daha iyi beslenmiş bir model onları geçebilir.
Bu arada parametre sayısıyla övünmek 2023 modası. 2026'da kimse "kaç parametren var" demiyor, "ne kadar veriyle, ne kadar uzun süre eğittin" soruluyor. Chinchilla bunu gösterdi ve büyüklük yarışı sessizce bitti. Pratik sonuç: 2026'da bir 7B parametre model, 2022'nin 70B'ından sık sık daha iyi performans veriyor.
Quantization (Niceleme)
Bir 7B modelini eğitirken her parametre 16-bit (2 byte) tutulur — yani ~14 GB. Bunu çalıştırırken 4-bit'e indirebiliyorsun (Q4_K_M). Aynı 7B model artık ~4 GB, ve kalite kaybı çok az. 16 GB RAM'li bir dizüstüde rahat çalışıyor. Yerel LLM ekosisteminin temel taşı bu.
"Trilyon" Ne Kadar?
Trilyon parametre — kulağa beyin gibi geliyor, değil. İnsan beyninde ~86 milyar nöron, ~100-500 trilyon sinaps var. Sinapslarla parametreyi yan yana koyduğunda biyolojik olan hâlâ 100 kat önde. Üstelik sinaps zamansal, kimyasal, üç boyutlu; parametre tek bir kayan nokta sayısı. Numaranın büyüklüğüne kanıp "modeller artık düşünüyor" demeye kalkma — sayı büyüdü, fizik aynı.
Embedding — Anlamı Sayıya Çevirmek
Buraya kadar token'lar (kelimeler) ve parametreler (düğmeler) var. Arada bir köprü gerek: model token'ları sadece tamsayı ID olarak görür ("cat" → 4842). Ama matematiği vektörlere çalışıyor. Token'ı vektöre çeviren katmana embedding layer denir.
Embedding nedir: anlamı temsil eden bir sayı listesi (vektör). Tipik boyutlar 768, 1024, 1536 veya 3072. Her metin yüksek-boyutlu bir uzayda bir nokta. Anlamca benzer şeyler birbirine yakın, alakasız şeyler uzak.
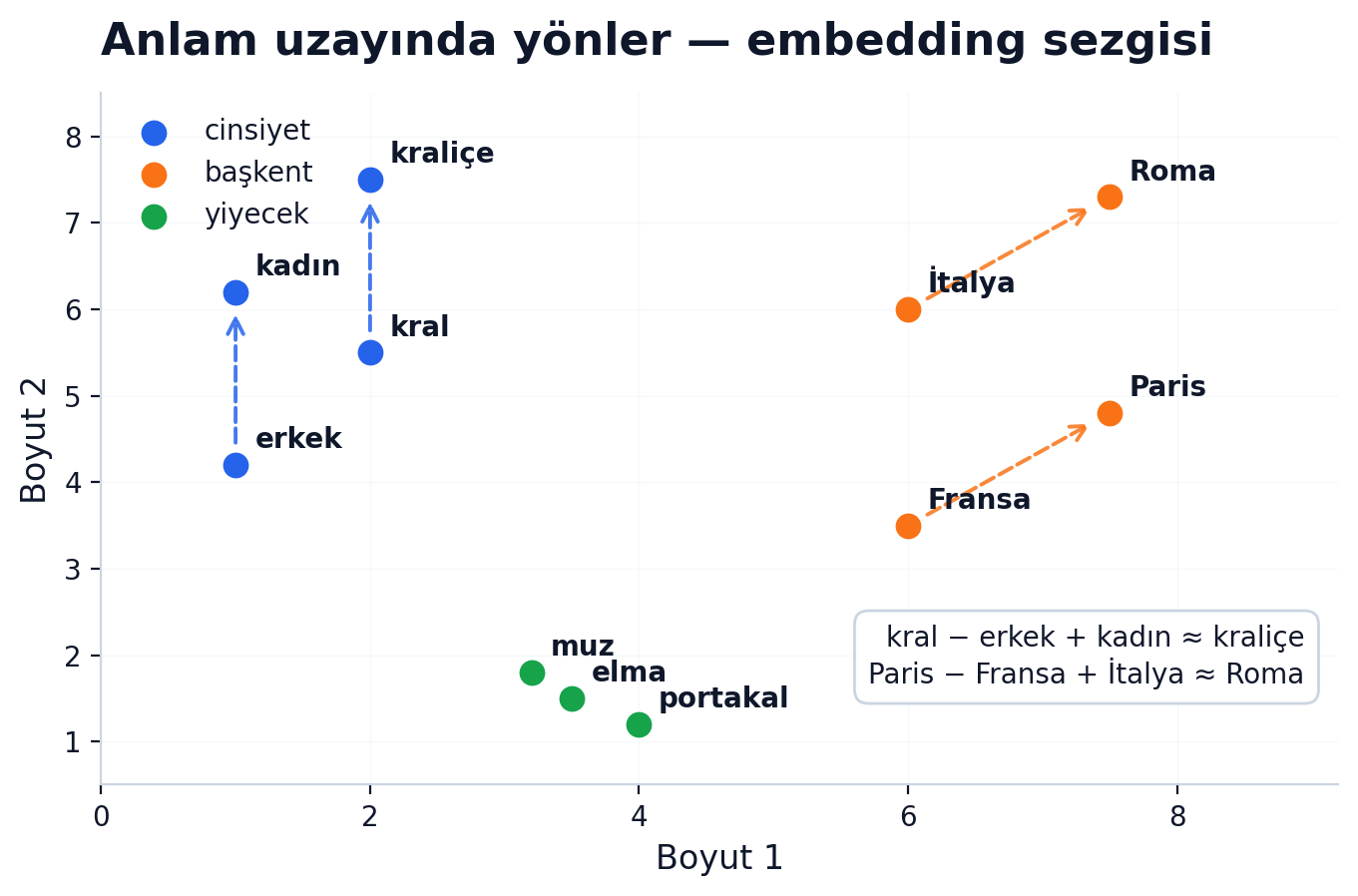
Buna inanması zor, biliyorum — ama 2013'te Word2vec bu fikri popülerleştirdi:
kral − erkek + kadın ≈ kraliçe
Yani vektör uzayında "cinsiyet" diye bir yön var. "Kral"dan "erkek" yönünü çıkartıp "kadın" yönünü eklediğinde "kraliçe"ye geliyorsun. Aynısı: Paris − Fransa + İtalya ≈ Roma. (Küçük dürüst not: bu gösterim, standart testte üç girdi kelimesi [kral, erkek, kadın] cevap kümesinden çıkarıldığı için bu kadar temiz görünür; yine de sezgi doğru.)
Modern LLM'lerde ilk katman embedding katmanı. Her token önce ~3072 boyutlu bir vektöre haritalanır, sonra onlarca transformer katmanı bu vektörü bağlam üzerinde dönüştürür. Embedding katmanı anlam dünyasına geçtiğin kapı.
Embedding'ler ayrı bir ürün olarak da satılıyor. 2026 liderleri:
- Google gemini-embedding-001 — 3072 boyut, 100+ dil, MTEB lideri
- OpenAI text-embedding-3-large — 3072 boyut
- Cohere embed-v4 — multimodal (resim + metin aynı uzayda)
- Qwen3-Embedding-8B — açık ağırlık, multilingual MTEB #1
İki metnin ne kadar yakın olduğunu cosine similarity ile ölçeriz: vektörlerin arasındaki açının kosinüsü. −1 (zıt) ile +1 (aynı yön) arası.
Embedding'ler RAG'in temelini oluşturuyor (birazdan göreceğiz) ve multimodal çalışıyor. CLIP modeli (OpenAI, 2021) bir köpek fotoğrafıyla "a photo of a dog" metnini aynı vektör uzayına yerleştiriyor; sonuçta bir fotoğraf koleksiyonunda Türkçe bir cümleyle arama yapabilirsin. Sihir değil — çekirdeği cosine similarity, birkaç satır numpy. Tek farkı, embedding'leri eğitmek için birinin bir milyar dolar yakmış olması.
Geçen sene bir projemde kendi blog yazılarımı embedding'e çevirip pgvector'da sorguladım. "WebGPU" yazınca, içinde "WebGPU" kelimesi hiç geçmeyen ASCII shader yazısı ilk sıraya geldi. O an embedding'in indeks değil, anlam haritası olduğuna ikna oldum.
Context Window — Modelin Kısa Vadeli Hafızası
Bir LLM bir sohbet sırasında bir şey hatırlamaz. Her seferinde sıfırdan, sadece o anda görebildiği token'lara bakıyor. Görebildiği toplam token sayısına context window (bağlam penceresi) deniyor.
Bu pencereye giren her şey context'i tüketir:
- Sistem mesajın ("Sen yararlı bir asistansın...")
- Sohbet geçmişi
- Yapıştırdığın dosyalar/PDF'ler
- RAG ile enjekte edilen belgeler
- O an üretmekte olduğu cevap
Pencere dolduğunda model eski şeyleri unutuyor veya sıkıştırıyor. Modelin masası gibi düşün — masada olmayan şey, o tur için yok.
Mayıs 2026 rakamları:
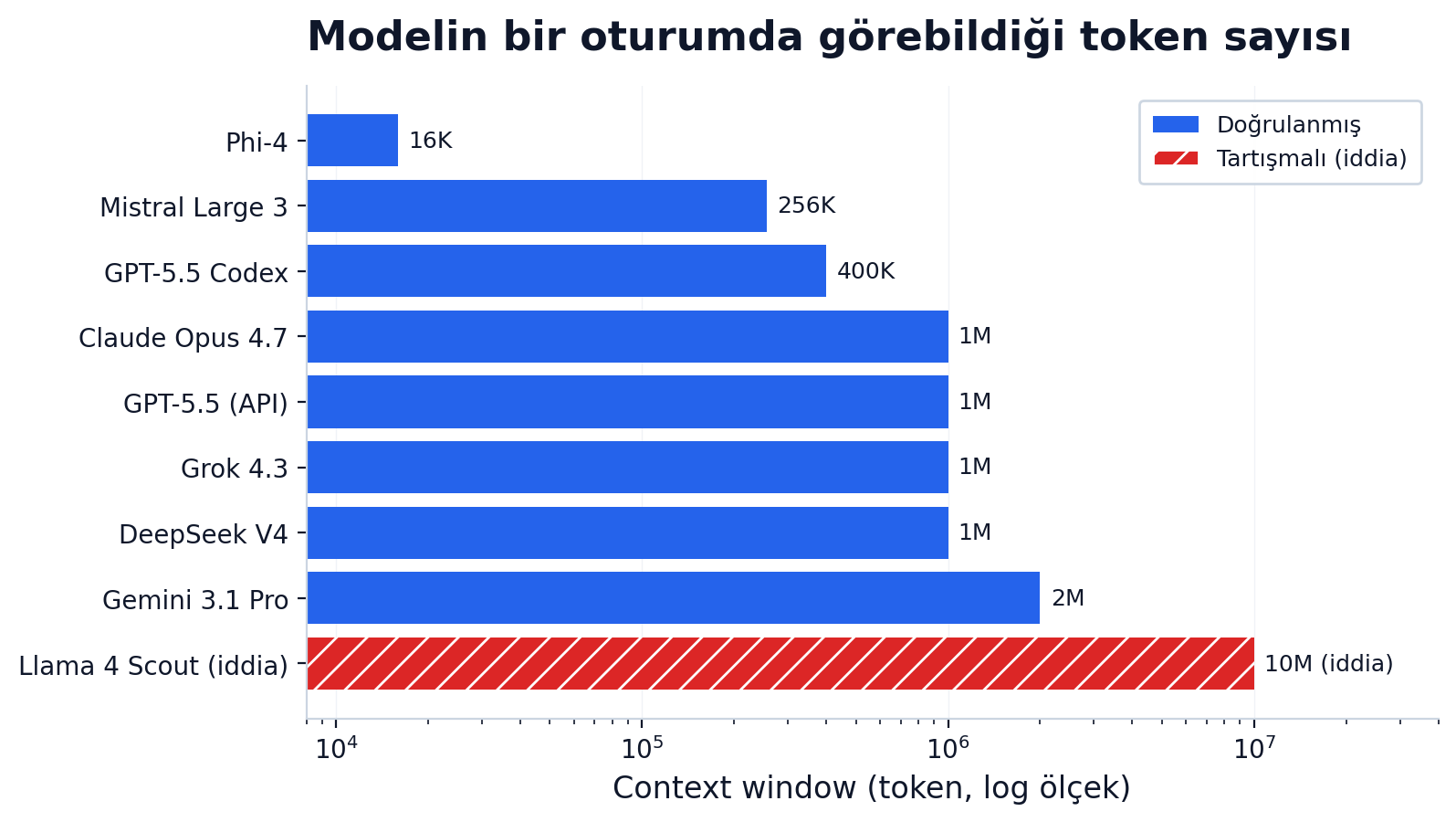
Bir tuzak: "1M context" diye reklam yapıyorlar ama pratikte modeller orta kısmı kaybediyor. Başını ve sonunu okuyor, ortadaki 600 sayfaya nazar atıyor sadece. Buna "lost in the middle" (Liu vd., 2023) deniyor.
Üstelik context'i sadece taşıyabilirsin diye doldurmak ucuz değil. İlk 1M context'i denediğimde naive olarak bütün repo'yu yapıştırdım — 800K token. Model girişe 11 saniye, ilk token'a 14 saniye sonra başladı. O gün dersi aldım: bağlam pencerene "her şeyi at" tavrıyla yaklaşma, seçici besle.
Attention — Modelin Gerçekte Ne Yaptığı
Bir cümleyi anlamlandırmanın sırrı attention (dikkat) mekanizmasında. 2017'de Google'ın "Attention Is All You Need" makalesi çıktı — ve dürüst olalım, o tarihten önce yazılmış her LSTM tabanlı dil modeli kodunu artık müzeye kaldırabilirsin. Transformer her token'ın diğer her token'a aynı anda bakmasına izin verdi.
Sezgi: "Kıyıdaki banka dik" cümlesinde "banka"yı anlamak için modelin "kıyı" ve "dik" kelimelerine daha çok ağırlık vermesi, "para" kavramına az ağırlık vermesi lazım. Attention bunu sayısal yapıyor — her token diğer her token için bir "ne kadar dikkat edeyim" skoru üretiyor.
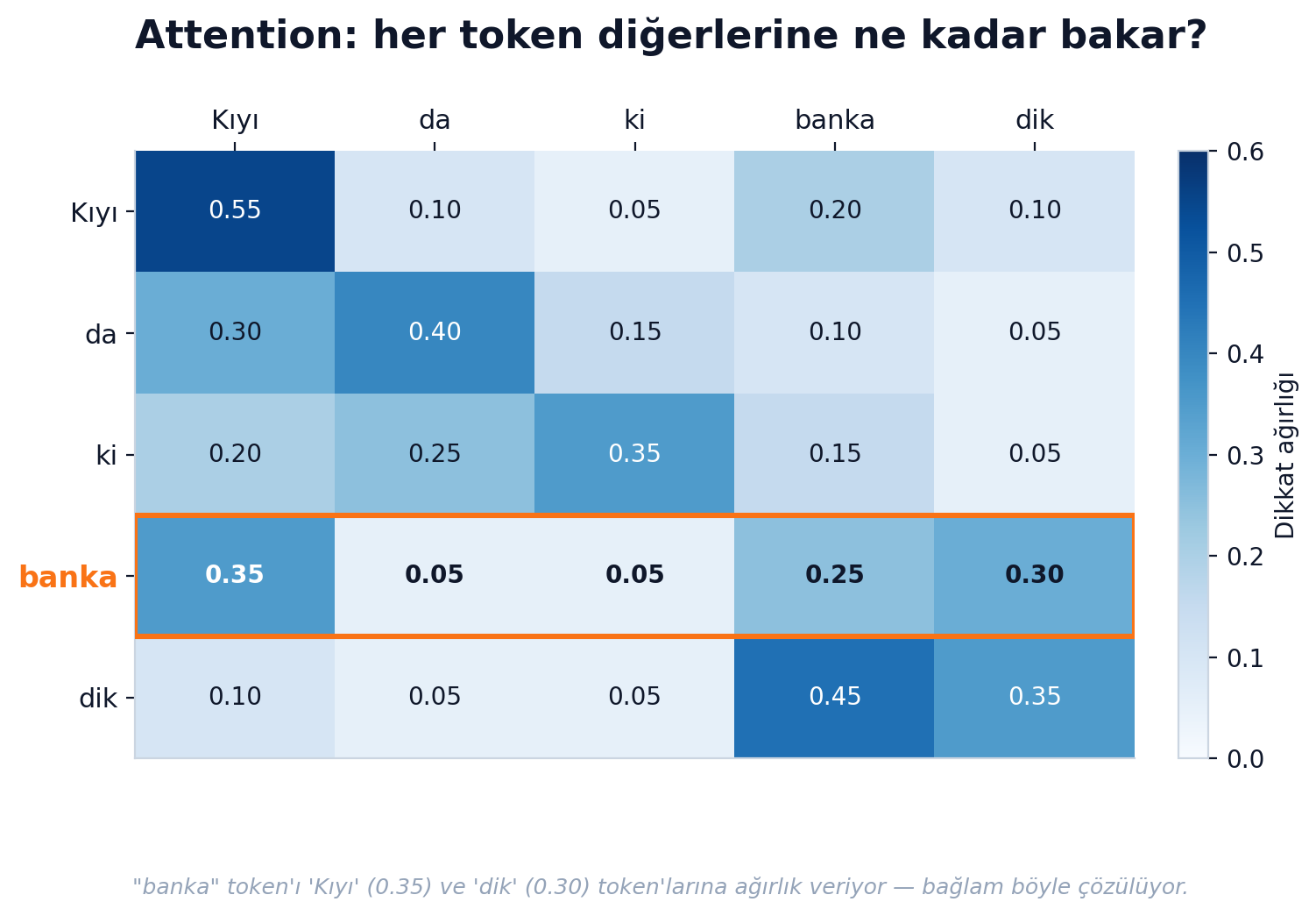
Bu işlem paralel yapılabildiği için GPU'larda hızla eğitilebiliyor. Modern LLM patlamasının teknik temeli budur.
Attention'ı sezgi olarak içselleştirdiğim an Karpathy'nin tensor üzerinde elle yazdığı 8-satırlık softmax(QK^T / sqrt(d)) V parçasını sayfaya yazdığım gündü. O sekiz satır olmasaydı LLM patlaması da olmazdı.
Prompt — Ne Yazdığın Önemli
Prompt = modele yazdığın metin. Chat arayüzleri prompt'u üç role böler:
- System prompt — sürekli geçerli olan talimatlar (kimlik, kurallar, ton): "Sen bir SQL uzmanısın, kısa cevap ver"
- User message — sen
- Assistant message — modelin cevabı (sonraki turlarda geçmiş olarak geri besleniyor)
Çok basit ama etkili bir hile: cevap istediğin şey karmaşıksa "adım adım düşün" veya "önce muhakemeni göster, sonra son cevabı ver" ekle. Bu tekniğin adı chain-of-thought (düşünce zinciri). Model kendi ara çıktısını karalama kâğıdı olarak kullanıyor ve doğruluk ciddi ölçüde artıyor. 2026'nın "thinking" modelleri (Claude extended thinking, GPT-5.5 Thinking, Gemini 3 Deep Think, DeepSeek R1) bunu otomatik içeride yapıyor.
Kendi tecrübemden pratik kurallar:
- Spesifik ol. "Bir hikâye yaz" yerine "noir tonda, 200 kelimelik, İstanbul'da geçen polisiye paragraf yaz".
- Örnek ver (few-shot). Tonu yakalamasının en hızlı yolu.
- Format söyle. "Markdown tablo halinde", "yalnızca JSON", "her madde tek cümle".
- Olumsuzlama kötü. "X yapma" yerine "Y yap" daha iyi sonuç verir.
Bu kuralları takip etmeye başladıktan sonra prompt'larım iki kat daha uzun, cevaplar üç kat daha kullanışlı oldu. Kısa prompt diye bir kahramanlık yok; sıkıştırılmış prompt vasat cevap üretir.
Hallucination — Modelin Kafadan Atması
Buna kibarca "hallucination" diyorlar. Türkçesi: model sıkıştığında kafadan sallıyor, hem de yüzünü kızartmadan. Hayali kitap referansı, var olmayan API fonksiyonu, yanlış tarih, uydurma alıntı.
Geçen hafta GPT-5.5 bana aiohttp-streaming diye bir kütüphane önerdi, örnek kodla beraber. Çok güzel kodluyordu. Tek sorun: o kütüphane var olmuyor. PyPI'da yok, GitHub'da yok, hiçbir yerde yok. Model uydurmuş ve eline kâğıt kalem alıp imzalamış.
Neden oluyor? Çünkü model bir veritabanı değil. İçinde "doğru cevaplar tablosu" yok. Yaptığı tek şey eğitim verisindeki kalıplara bakıp bir sonraki istatistiksel olarak makul token'ı üretmek. Sorduğun konuda veri yetersizse, model yine de en mantıklı görünen cümleyi kurar — ve o cümle uydurma olabilir.
Halüsinasyon bir sonraki versiyonda yamayla geçecek bir bug değil — mimarinin omurgasında. OpenAI bile kendi Eylül 2025 makalesinde (Why Language Models Hallucinate, özeti) "değerlendirme süreçlerimiz blöfü ödüllendiriyor" diye itiraf ediyor. Test puanı = 0 ile "bilmiyorum" denmez, tahmin = en azından kazanma şansı var. Modeller bu yüzden blöf yapmayı öğreniyor. Bunu okuduğumda iki şey hissetmiştim: birincisi "tahmin etmiştim", ikincisi "demek ki yıllarca böyle kalacak".
Beginner kuralı: Bir LLM'in söylediği her tarih, sayı, isim, alıntı veya API çağrısını birinci elden kaynakla doğrulamadan kullanma.
Yaygın yanlış anlamalar — kısa liste
- "LLM internete bağlı bir veritabanıdır." Değil. Eğitim verisi bir kesim tarihinde donmuş; "web search" gibi araçlar bağlanırsa o ayrı.
- "Büyük context her zaman iyidir." Değil. Lost-in-the-middle. Ayrıca her token para.
- "Halüsinasyon RLHF ile çözülür." Çözülmüyor. RLHF ton ayarlıyor, fact-checker eklemiyor.
Pretraining, Fine-tuning, RLHF
LLM yapmak üç aşamalı bir iş:
-
Pretraining (ön-eğitim): trilyonlarca token (internet, kitaplar, kod) üzerinde self-supervised next-token prediction. Aylar süren GPU eğitimi, on milyonlardan yüz milyonlara dolar maliyet. Çıktı: base model — dili biliyor ama henüz asistan değil.
-
Fine-tuning (SFT): çok daha küçük, özenle seçilmiş veriyle eğitime devam. Modeli bir alana (tıp, hukuk, müşteri desteği) veya tona uyarlar. Açık ağırlıklı modellerde sen de yapabilirsin.
-
RLHF / DPO: insan değerlendirmelerinden öğren. İnsanlara modelin iki cevabı gösterilir, hangisini tercih ettikleri sorulur. Model bu tercihleri yakalayacak şekilde ayarlanır. Yararlı, zararsız, dürüst asistan kişiliği bu aşamada şekilleniyor. Anthropic burada Constitutional AI denen kendi tekniğini kullanıyor.
RAG — Modelin Bilmediğini Öğretmek
Modelin eğitim verisinin bir kesim tarihi var. ChatGPT'ye "bugünkü hava nasıl?" dediğinde bilmiyor, çünkü kendi başına internete bağlı değil. RAG bu sorunu çözer.
Retrieval-Augmented Generation = sorgu zamanında ilgili belgeleri modelin context'ine enjekte etmek.
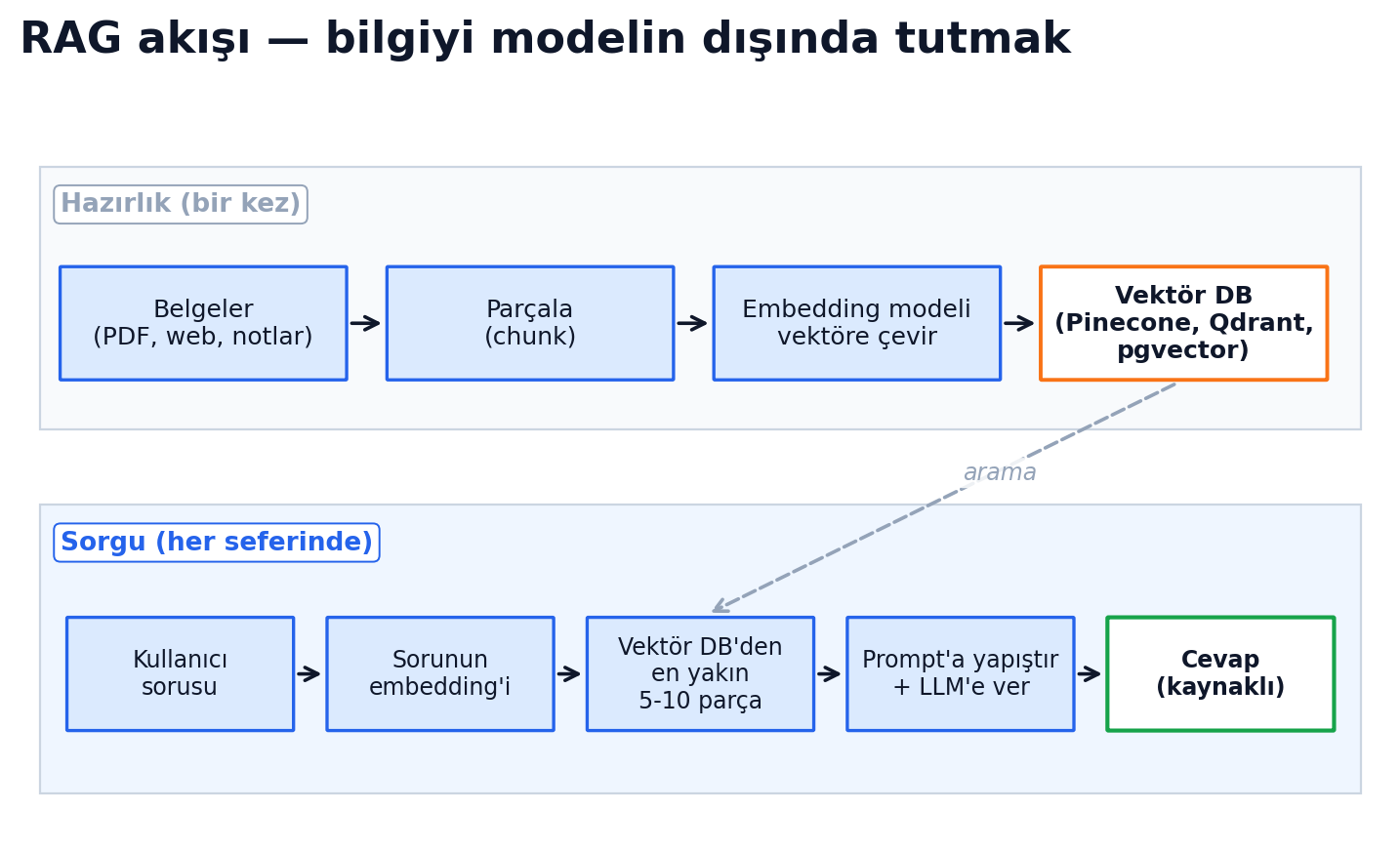
Niye iyi: model artık o özel belgelere referansla cevap veriyor. Halüsinasyon dramatik şekilde düşer, kaynak gösterebilir, yeni veri eklemek için modeli yeniden eğitmek gerekmez.
RAG vs Fine-tuning:
- RAG = bilgiyi değiştirmek için (yeni haberler, şirket içi belgeler)
- Fine-tuning = davranışı/üslubu değiştirmek için (hukuki ton, özel format)
İkisi rakip değil, beraber kullanılır. Pratikte gördüğüm hata sırası şu: insanlar önce fine-tuning'e koşuyor, halbuki istedikleri davranış değişikliği değil bilgi enjeksiyonu. Hangi kovaya atılacağı belli olunca proje aniden bir hafta kısalıyor.
Training vs Inference — İki Farklı Dünya
- Training bir kez olur. Aylar sürer. Sınır modeller için $10M-$1B+. Çıktısı parametre dosyaları.
- Inference her sorguda olur. Milisaniyeler. Soru başına kuruşlar.
Sen bir API kullanıcısı olarak hep inference'a para ödüyorsun. Claude 4.7'nin $5 input / $25 output ücreti = inference maliyeti. Eğitimin parasını OpenAI/Anthropic karşıladı.
Temperature ve Top-p — Yaratıcılık Düğmeleri
Çoğu API'de iki parametre görürsün:
- Temperature: 0 → en olası token'ı seç (deterministik). 0.7-1.0 → daha rastgele, yaratıcı. 0 koy, aynı soruya hep aynı cevap. 1 koy, her seferinde farklı.
- Top-p (nucleus sampling): kümülatif olasılığı
p(genelde 0.9) eden en küçük token kümesinden örnekle.
Yaratıcı yazı için 0.7-0.9. Kod veya gerçek bilgi için 0.0-0.2.
GPT, Llama, Mistral, Claude, Gemini — Hangisi Ne?
Bu modeller aynı temel mimaride (Transformer) ama eğitim verisi, ince-ayar tarzı, mimari detaylar ve ekosistemleri farklı. Mayıs 2026 manzarası:
Kapalı Kaynak Liderler
OpenAI — GPT-5.5 (Nisan 2026): Şu an default ChatGPT modeli. OpenAI, GPT-5.5 Instant'ın selefi GPT-5.3 Instant'a kıyasla yüksek-riskli (tıp, hukuk, finans) sorularda %52.5 daha az halüsinasyon ürettiğini belirtiyor — bu, OpenAI'ın kendi iç değerlendirmesi, bağımsız bir denetim değil. Varyantlar: GPT-5.5 Instant (free), GPT-5.5 Thinking (Plus/Pro), GPT-5.5 Pro. En geniş dağıtıma sahip ekosistem.
Anthropic — Claude Opus 4.7 (16 Nisan 2026): 1M context'i standart fiyatla verdi (uzun-bağlam ek ücreti yok). Kodlama ve agentic görevlerde lider — burada agent, bir hedefe ulaşmak için araçları (terminal, tarayıcı, dosya sistemi) kendi başına kullanıp çok adımlı işi yürüten LLM demek. "Bilgisayar başına oturt, 4 saatte modülünü yazsın" tarzı işler için tercih. Token başına $5 / $25; güncel tarife Anthropic fiyatlandırma sayfasında.
Google — Gemini 3 / 3.1 Pro: multimodal (metin + resim + ses + video) en güçlü model. Gemini 3 Deep Think paralel hipotez incelemesi yapıyor. API fiyatları: Google AI fiyatlandırma.
xAI — Grok 4.3 (Nisan 2026): "Her zaman düşünüyor". 1M context, video girişi, ses klonlama. SuperGrok Heavy aboneliği aylık $300.
Açık Ağırlıklı (İndir ve Çalıştır)
Meta — Llama 4 (Nisan 2025): Scout (10M context, hafif) + Maverick (128 expert, multimodal). MoE. Hugging Face'ten ücretsiz.
Mistral — Mistral Large 3 (Aralık 2025): 675B toplam / 41B aktif, 256K context. AB merkezli. Codestral kod modeli ayrı.
DeepSeek — V4 (Nisan 2026) + R1: Çinli takım. R1, Ocak 2025'te batıyı şoke etti çünkü pure-RL ile o1-seviyesi reasoning'i çok ucuza üretti. MIT lisanslı. (Karışmasın: V4 amiral modeldir; API tablosunda gördüğün ucuz V3.2 ise bir önceki neslin maliyet-optimize sürümü — DeepSeek fiyatlandırma.)
Alibaba — Qwen 3.6 (Nisan 2026): Alibaba'nın belirttiğine göre 201 dil desteği (üretici iddiası) — çok dilli işlerde güçlü. Türkçe için açık-kaynak tarafında en iyi seçeneklerden biri.
Microsoft — Phi-4: 14B dense, matematik/mantık odaklı. Telefonda bile çalışabilen Phi-4-mini var.
Açık olayım — günlük olarak ne kullanıyorum
Kod için Claude Opus 4.7, hızlı soru-cevap için ChatGPT, uzun PDF özetlemek için Gemini 3 Pro, Türkçe çeviri için Qwen 3.6 (sürpriz şekilde Türkçesi en temiz olan o). Hiçbir model her şeyde en iyi değil ve bunu sana satan herkes yalan söylüyor.
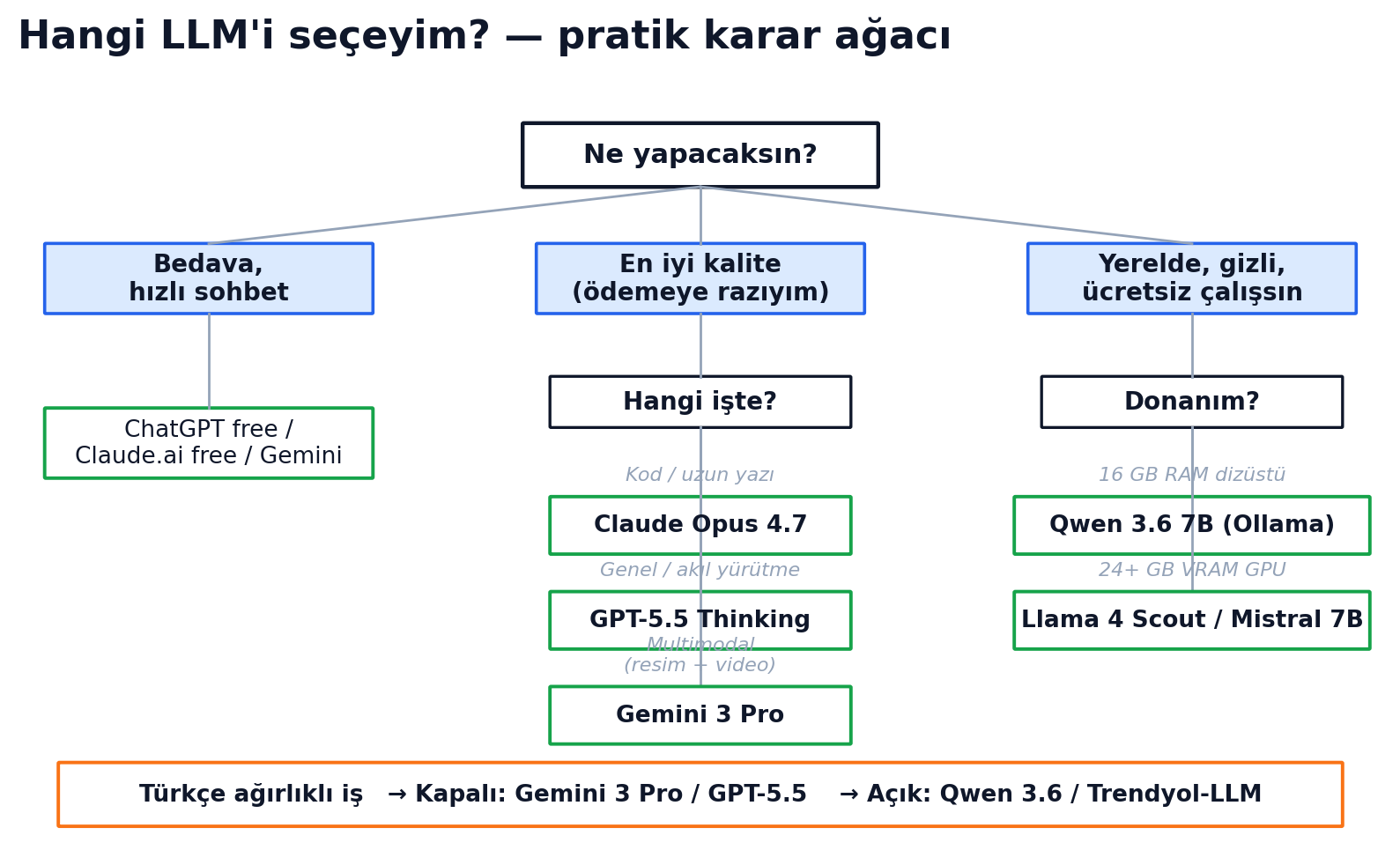
Kapalı vs Açık — Beginner İçin Ne Demek?
- Kapalı: API'ye veya web'e bağlanırsın. Token başına ödersin. Ağırlıklar şirkette kalır. Sıfır kurulum, sınır kalite. Teknik olmayan kullanıcı için kazanan.
- Açık ağırlık: Hugging Face'ten indirirsin. Kendi bilgisayarında çalıştırırsın. Doların yok, donanım masrafın var. 7B Q4 model 16 GB'lık dizüstüye sığar. 70B için 24+ GB VRAM'lik GPU veya Apple Silicon Mac unified memory.
Hangisini Kullanmalıyım?
| Senaryo | Tavsiye |
|---|---|
| Türkçe özelinde | Closed: Gemini 3 Pro, GPT-5.5. Açık: Qwen 3.6 veya Türkçe fine-tune'lar (Trendyol-LLM, WiroAI) |
| Bedava, tarayıcıda hızlı sohbet | ChatGPT free, Claude.ai free, Gemini, Copilot |
| En iyi genel performans | Claude Opus 4.7 (yazı/kod), GPT-5.5 Thinking (genel), Gemini 3 Pro (multimodal) |
| Dizüstünde yerelde çalıştır | Qwen 3.6 8B (Ollama: qwen3), Llama 3.1 8B (Llama 3.3 yalnızca 70B'dir, dizüstüne ağır), Phi-4-mini (Ollama ile) |
| Projende API olarak kullan | Claude Sonnet 4.6 (ucuz + güçlü), GPT-5.5-mini, DeepSeek V3.2 (~10× ucuz), Mistral (AB veri) |
Yerel LLM Ekosistemi
Dizüstüne LLM kurmak istersen şunları duyacaksın:
- llama.cpp — Georgi Gerganov'un C/C++ inference motoru. CPU, CUDA, Metal, Vulkan, hepsinde çalışır. Tüm yerel ekosistemin altyapısı.
- GGUF — llama.cpp'nin dosya formatı. Tek dosyada ağırlık + tokenizer + meta. Genelde 4-bit quantize halinde dağıtılır.
- Ollama —
ollama run qwen3gibi bir komutla model çalıştırırsın. (Not:llama3.3yalnızca 70B'dir ve ~43 GB'tır, dizüstüne ağır gelir; küçük yerel iş içinqwen3:8b,llama3.1:8bveyagemma3tercih et.) OpenAI-uyumlu yerel API sunar. Geliştirici için ideal. - LM Studio — GUI'li alternatif. Hugging Face entegre, tıkla-indir. Teknik olmayan kullanıcı için iyi.
- Jan — açık kaynak ChatGPT yerine geçen masaüstü uygulaması.
Ben günlük olarak M2 Pro üstünde Qwen 3.6'yı (Ollama'da qwen3, 8B) çalıştırıyorum. İlk token gecikmesi 300ms, sonrası saniyede ~35 token. Bu sayılar 2023'te aklın alacağı bir şey değildi. Apple'ın unified memory mimarisi, hiç planlamadığı bir şekilde yerel LLM ekosistemini kurtardı.
10 dakikalık deneme: Ollama indir, ollama run qwen3:8b yaz, Türkçe konuş. Dizüstünde yerel, ücretsiz, internetsiz.
Sırada Ne Öğrenmeli?
Bu sözlük temel. İlerlemek istiyorsan şu sırayı öneririm:
- 3Blue1Brown'ın "Neural Networks" oynatma listesi (YouTube) — görsel ve hafif matematikle transformer'ı anlatıyor. Türkçe altyazı var.
- Andrej Karpathy'nin "Let's build GPT" videosu — sıfırdan minik bir GPT kodluyor. Python bilmek yeterli.
- Bir RAG sistemi kur — LangChain veya LlamaIndex ile 50 PDF üzerinde soru-cevap robotu. En öğretici proje.
- Bir modeli fine-tune et — Hugging Face + Unsloth ile Llama 3'ü kendi Türkçe verinle ince ayar yap.
Kaynaklar ve Daha Fazlası
Yazıdaki temel iddiaların birinci-el kaynakları (kesim tarihinden sonrası için resmi sayfaları teyit et):
- Transformer: Attention Is All You Need — Vaswani vd., 2017
- Ölçek yasaları: Training Compute-Optimal LLMs (Chinchilla) — Hoffmann vd., 2022
- Embedding analojisi: Efficient Estimation of Word Representations (Word2vec) — Mikolov vd., 2013
- Uzun bağlam: Lost in the Middle — Liu vd., 2023
- Tokenizer'sız modeller: Byte Latent Transformer — Pagnoni vd., 2024
- Halüsinasyon: Why Language Models Hallucinate — Kalai vd., 2025 (OpenAI özeti)
- Güncel fiyatlar: OpenAI · Anthropic · Google Gemini · DeepSeek
- Token sayacı: OpenAI Tokenizer
Kapanış
Buraya kadar geldiysen artık benim akrabamdan birkaç kademe öndesin — telefonda "kestim seni" diyemeyeceği bir noktadasın. Daha önemlisi: bir sonraki "AI X yapacak" başlığını gördüğünde hangi katmanda konuşulduğunu, neyin mimari neyin pazarlama olduğunu ayırt edebiliyorsun.
Aklında tek cümle kalacaksa: çoğu LLM kavramı, jargon kabuğunu soyduğunda istatistik + lineer cebir + biraz mühendislik. Mistik bir şey yok — sadece çok büyük, çok iyi tahmin etmesi öğretilmiş bir makine.
Ödevin var: bu yazıdan ilgini çeken bir kavram seç, ChatGPT veya Claude'a önce "bunu 5 yaşındaki çocuğa anlat", sonra "şimdi profesyonele anlat" de. Aradaki farkı oku.
Akrabam hâlâ ChatGPT'yi "şu yazı yazan şey" diye anıyor. Belki bir gün ona da bu yazıyı okuturum — hâlâ telefonu kapatacak diye korkuyorum.
Bu yazıyı yazarken bir agent takımı kullandım: bir ses denetçisi, bir görsel mimar ve bir Python ressamı paralelde çalıştı; yukarıdaki sekiz şema da o ekipten çıktı. Bir sonraki yazıda RAG'i sıfırdan, satır satır kuracağız.
Finis